Introdução4.1
Iniciamos agora um estudo detalhado sobre o projeto e a construção de sistemas operacionais, focando naquele que é considerado o conceito mais central desta área: o processo. Trata-se de uma abstração de um programa em execução, sendo que todos os demais elementos dependem dessa definição. O projetista e o estudante de sistemas operacionais devem desenvolver uma compreensão profunda sobre o que constitui um processo o mais cedo possível, visto que esta é uma das abstrações mais antigas e vitais fornecidas por esses sistemas.
Processos dão suporte à possibilidade de haver operações pseudoconcorrentes mesmo quando existe apenas uma CPU disponível, transformando uma única unidade física de processamento em múltiplas CPUs virtuais. Sem a abstração de processo, a computação moderna não poderia existir.
Neste contexto, examinaremos detalhadamente os processos e seus "primos", os threads. Ao observarmos o funcionamento dos computadores modernos, notamos que eles frequentemente realizam várias tarefas ao mesmo tempo. Embora usuários habituados possam não estar totalmente cientes desse fato, a análise de cenários práticos ajuda a esclarecer este ponto, conforme ilustrado nos exemplos a seguir:
1. O Servidor Web
Solicitações de páginas chegam de toda parte. Ao receber uma requisição, o servidor verifica se a página está em cache. Se estiver, ela é enviada imediatamente. Caso contrário, inicia-se uma solicitação de acesso ao disco. Como o acesso ao disco é lento do ponto de vista da CPU, muitas outras solicitações podem chegar durante essa espera. Com múltiplos discos, novas solicitações podem ser processadas antes mesmo da conclusão da primeira.
2. O Computador Pessoal (PC)
Ao inicializar o sistema, muitos processos são iniciados secretamente (background). Um processo pode aguardar e-mails, enquanto outro executa o antivírus periodicamente. Simultaneamente, o usuário pode imprimir arquivos e salvar fotos em um pen-drive enquanto navega na Web. Toda essa atividade requer um sistema de multiprogramação robusto para ser gerenciada.
É evidente que é necessário um método para modelar e controlar essa concorrência, e é aqui que processos e threads desempenham um papel crucial. Em qualquer sistema de multiprogramação, a CPU alterna de um processo para outro rapidamente, executando cada um por dezenas ou centenas de milissegundos.
Estritamente falando, em um dado instante a CPU executa apenas um processo, mas no curso de um segundo ela pode trabalhar em vários deles, criando uma ilusão de paralelismo. Para diferenciar essa alternância rápida do paralelismo físico real, utilizamos terminologias distintas detalhadas na tabela abaixo:
| Conceito | Descrição Técnica | Hardware Típico |
|---|---|---|
| Pseudoparalelismo | A CPU alterna rapidamente entre processos, criando a ilusão de simultaneidade. | Uma única CPU compartilhando tempo. |
| Verdadeiro Paralelismo | Múltiplas instruções são executadas literalmente ao mesmo tempo em unidades físicas distintas. | Sistemas multiprocessadores (duas ou mais CPUs compartilhando memória). |
Como ter controle sobre múltiplas atividades em paralelo é uma tarefa complexa para os seres humanos, os projetistas de sistemas operacionais desenvolveram ao longo dos anos o modelo conceitual de processos sequenciais. Esse modelo torna o paralelismo mais fácil de lidar, e suas consequências compõem a base para o entendimento profundo do gerenciamento de sistemas computacionais.
O modelo de processo4.1.1
Nesse modelo, todos os softwares executáveis no computador, incluindo frequentemente o sistema operacional, são organizados em uma série de processos sequenciais. Um processo é, fundamentalmente, uma instância de um programa em execução, contendo os valores atuais do contador do programa, registradores e variáveis. Conceitualmente, cada processo possui sua própria CPU virtual. Na realidade, a CPU física alterna entre os processos constantemente, mas, para fins de compreensão do sistema, é mais simples imaginar uma coleção de processos sendo executados em pseudo-paralelismo do que tentar rastrear a troca frenética da CPU. Esse mecanismo de alternância rápida é denominado multiprogramação.
A visualização desse conceito é essencial para distinguir entre a perspectiva física e a lógica. A figura a seguir ilustra essa distinção, mostrando como a memória organiza os programas e como o fluxo de controle é percebido:
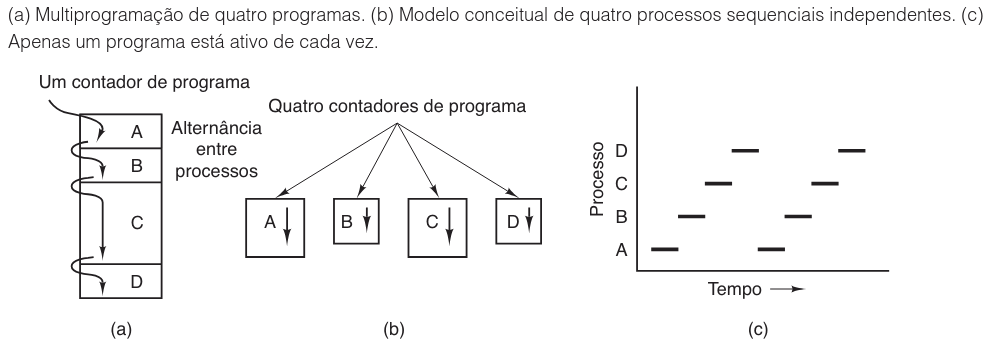
Ao analisar a imagem acima, observamos em (a) um computador multiprogramando quatro programas na memória. Em (b), vemos quatro processos, cada um com seu próprio contador de programa lógico e fluxo de controle, sendo executados independentemente. Embora exista apenas um contador de programa físico, seu valor é salvo no contador lógico do processo na memória sempre que a execução é interrompida e restaurado quando ela retorna. Em (c), nota-se que, ao longo do tempo, todos os processos progridem, embora apenas um esteja ativo em um dado instante.
Embora a maioria das CPUs modernas seja multicore (com dois ou mais núcleos), assumiremos neste capítulo, para fins de simplificação, a existência de apenas uma CPU. O princípio permanece o mesmo: mesmo com dois núcleos, cada um só pode executar um processo por vez.
Com o chaveamento rápido da CPU, a velocidade de execução de um processo não é uniforme nem necessariamente reproduzível. Processos não devem ser programados com suposições rígidas sobre tempo.
Exemplo Prático: Considere um processo de áudio que deve tocar música sincronizada com um vídeo. O processo pode iniciar um loop ocioso para aguardar o momento exato. Se a CPU trocar de processo durante esse loop, o áudio poderá retornar atrasado, perdendo a sincronia com o vídeo. Para sistemas de tempo real com prazos críticos (em milissegundos), medidas especiais são necessárias.
A distinção entre um processo e um programa é sutil, porém crucial. Um programa é uma entidade passiva (como um arquivo em disco), enquanto um processo é uma entidade ativa. Para ilustrar essa diferença, utilizamos uma analogia clássica:
Imagine um cientista da computação preparando um bolo de aniversário.
| Elemento da Cozinha | Conceito de S.O. |
|---|---|
| A Receita | O Programa (algoritmo expresso em notação). |
| O Cientista | O Processador (CPU). |
| Os Ingredientes | Os Dados de Entrada. |
| Preparar o Bolo | O Processo (a atividade em execução). |
Cenário de Interrupção: Se o filho do cientista entra chorando (uma interrupção de alta prioridade), o cientista registra onde parou na receita (salva o estado do processo atual) e muda para o "programa" de primeiros socorros. Ao terminar, ele recupera o estado salvo e continua o bolo.
Conclusão: Um processo é uma atividade com estado, entrada, saída e um programa. O processador é compartilhado entre vários processos através de um algoritmo de escalonamento.
Por fim, é importante notar que instâncias diferentes do mesmo programa são processos distintos. Se você abrir dois processadores de texto simultaneamente, haverá dois processos separados. Embora o sistema operacional possa otimizar o uso da memória compartilhando o código do programa, conceitualmente eles permanecem como duas linhas de execução independentes.
Criação de processos4.1.2
Sistemas operacionais necessitam de mecanismos eficientes para criar processos. Em sistemas muito simples ou projetados para uma única aplicação, como o controlador de um forno de micro-ondas, é possível que todos os processos necessários sejam carregados no momento em que o sistema é ligado. Contudo, em sistemas de propósito geral, é indispensável a capacidade de criar e terminar processos dinamicamente durante a operação.
Existem quatro eventos principais que desencadeiam a criação de processos, detalhados na tabela a seguir:
| Evento de Criação | Contexto e Descrição |
|---|---|
| Inicialização do Sistema | Ocorre quando o sistema operacional é carregado, criando processos essenciais de primeiro e segundo plano. |
| Chamada de Sistema | Um processo em execução solicita a criação de um novo processo para auxiliar em sua tarefa. |
| Solicitação do Usuário | O usuário inicia um programa via linha de comando ou interface gráfica (clique duplo). |
| Início de Tarefa em Lote | Em mainframes, o sistema inicia um processo automaticamente quando há recursos disponíveis para a próxima tarefa da fila. |
Durante a inicialização do sistema, diversos processos são iniciados. Alguns operam em primeiro plano, interagindo com usuários humanos, enquanto outros funcionam em segundo plano, desempenhando funções específicas como gerenciar e-mails ou servir páginas web. Estes processos de segundo plano, que permanecem inativos até serem solicitados, possuem uma denominação específica:
Processos que operam em segundo plano para lidar com atividades como e-mail, impressão e serviços web são chamados de daemons.
- No UNIX: O comando
pspode ser usado para listar esses processos. - No Windows: O Gerenciador de Tarefas desempenha função similar de visualização.
A criação de novos processos por um processo já existente é particularmente útil para dividir tarefas. Por exemplo, ao processar uma grande quantidade de dados de uma rede, um processo pode focar na busca dos dados enquanto um segundo processo os manipula, permitindo paralelismo real em sistemas multiprocessadores. Em sistemas interativos, ações simples como clicar em um ícone iniciam novos processos, que podem ou não abrir janelas visuais, dependendo do sistema operacional (UNIX ou Windows).
Do ponto de vista técnico, a criação sempre envolve uma chamada de sistema. A implementação dessa chamada varia drasticamente entre os sistemas operacionais UNIX e Windows, conforme comparado abaixo:
| Característica | UNIX (Posix, Linux, MacOS) | Windows (Win32) |
|---|---|---|
| Chamada Principal | fork |
CreateProcess |
| Mecanismo | fork cria um clone exato do processo pai. Posteriormente, execve é usado para carregar o novo programa. |
CreateProcess realiza tanto a criação quanto o carregamento do programa em uma única chamada. |
| Complexidade | Processo em dois passos. Permite manipulação de descritores de arquivos (redirecionamento de E/S) antes da execução do novo código. | Chamada única com cerca de 10 parâmetros (programa, segurança, prioridade, janelas, etc.). |
| Espaço de Endereço | Inicialmente, o filho é uma cópia do pai. Utiliza copy-on-write (cópia-na-escrita) para otimização. | Os espaços de endereços do pai e do filho são diferentes desde o início. |
É crucial notar que, em ambos os sistemas, após a criação, o processo pai e o processo filho possuem espaços de endereçamento distintos. Se um processo altera uma variável em sua memória, essa mudança não é visível para o outro. No UNIX, embora a memória possa ser compartilhada inicialmente para leitura via copy-on-write, qualquer tentativa de escrita provoca uma cópia física da página de memória, garantindo que a memória modificável nunca seja compartilhada inadvertidamente. Recursos como arquivos abertos, todavia, podem ser compartilhados dependendo da implementação.
Término de processos4.1.3
Após a criação e o início da execução, todo processo realiza sua função designada. No entanto, o ciclo de vida de um processo é finito; mais cedo ou mais tarde, ele deve terminar. Esse encerramento ocorre geralmente devido a uma de quatro condições principais, que variam entre a conclusão natural do trabalho e interrupções forçadas por erros ou intervenções externas.
A tabela abaixo detalha as causas fundamentais para o fim de um processo, classificando-as pela natureza da ocorrência:
| Motivo do Término | Natureza | Descrição e Contexto |
|---|---|---|
| 1. Saída Normal | Voluntária | O processo conclui sua tarefa com sucesso. Exemplo: um compilador termina a tradução do código ou o usuário fecha o navegador. |
| 2. Saída por Erro | Voluntária | O processo detecta um problema lógico (como um arquivo de entrada inexistente) e decide encerrar a execução de forma controlada. |
| 3. Erro Fatal | Involuntária | Ocorrem falhas graves decorrentes de bugs, como instrução ilegal, referência a memória inexistente ou divisão por zero. |
| 4. Morto por Outro | Involuntária | Um processo executa uma chamada de sistema para forçar o encerramento de outro processo (ex: Gerenciador de Tarefas). |
Quando um processo termina voluntariamente, ele comunica esse fato ao sistema operacional através de chamadas específicas: exit no UNIX e ExitProcess no Windows. Em aplicações interativas baseadas em tela, como processadores de texto, essa ação é desencadeada visualmente pelo usuário ao clicar em um ícone de fechar, o que permite ao software limpar arquivos temporários antes de sair.
A forma como o erro é tratado depende da interface do programa:
- Linha de Comando (Ex: Compilador): Se o usuário digita
cc foo.ce o arquivo não existe, o programa anuncia o erro e encerra imediatamente (Saída por Erro). - Interface Gráfica (Interativo): Geralmente não fecha o programa diante de dados incorretos. Em vez disso, exibe uma caixa de diálogo pedindo que o usuário tente novamente.
Nos casos de erro fatal, o sistema operacional intervém. No entanto, em alguns sistemas como o UNIX, um processo pode instruir o sistema de que deseja lidar com certos erros sozinho (capturando o sinal), evitando o término abrupto. Já no cenário de morte forçada por outro processo, é necessária a devida autorização de segurança. As chamadas utilizadas são kill (UNIX) e TerminateProcess (Win32).
Em alguns sistemas operacionais teóricos ou antigos, o encerramento de um processo pai acarretava a morte imediata de todos os seus processos filhos. É importante notar que nem o UNIX nem o Windows funcionam dessa maneira. Nesses sistemas modernos, os processos filhos continuam sua execução independentemente do destino de seu criador.
Hierarquias de processos4.1.4
Em diversos sistemas operacionais, a criação de um processo estabelece um vínculo duradouro entre o criador (pai) e a criatura (filho). À medida que o processo filho gera seus próprios descendentes, forma-se uma estrutura hierárquica. É fundamental observar que, diferentemente da biologia de animais que utilizam a reprodução sexual, um processo possui apenas um pai, embora possa ter zero ou múltiplos filhos.
A estrutura de reprodução de processos assemelha-se mais à de uma hidra (reprodução assexuada/brotamento) do que à de um mamífero ou uma vaca. A linhagem é direta e singular na origem.
No ambiente UNIX, essa hierarquia é rígida e funcional. Um processo e todos os seus descendentes constituem um grupo de processos. Essa estruturação permite, por exemplo, que um sinal enviado pelo teclado seja entregue simultaneamente a todos os membros do grupo associado àquela janela. Individualmente, cada processo tem autonomia para tratar esse sinal: capturá-lo, ignorá-lo ou aceitar a ação padrão (geralmente, o encerramento). A importância dessa árvore genealógica é visível na inicialização do sistema:
- O processo init é carregado na raiz da imagem de inicialização.
- Ele lê a configuração de terminais e realiza um fork (bifurcação) para criar um novo processo para cada terminal.
- Esses processos aguardam uma conexão bem-sucedida.
- Após o login, um shell é executado para aceitar novos comandos, expandindo a árvore.
Consequentemente, todos os processos em um sistema UNIX pertencem a uma única árvore global enraizada no init, e um pai nunca pode "deserdar" seus filhos. Em contrapartida, o Windows adota uma filosofia distinta, onde a hierarquia é muito mais tênue, conforme comparado na tabela a seguir:
| Característica | UNIX | Windows |
|---|---|---|
| Estrutura | Árvore única e rígida (Root/Init). | Plana. Todos os processos são essencialmente iguais. |
| Vínculo Pai-Filho | Permanente. O pai define o grupo de processos. | Temporário e transferível via Handles. |
| Controle | Baseado na ancestralidade direta. | Baseado na posse do token (handle) de controle. |
| Herança | Processos não podem ser deserdados. | O handle pode ser passado a outro processo, invalidando a hierarquia original. |
No Windows, o único vestígio de hierarquia surge na criação, quando o pai recebe um identificador especial (handle) para controlar o filho. Contudo, como esse identificador pode ser transferido livremente para terceiros, a noção de "família" se dissolve, permitindo que qualquer processo que possua o handle controle a execução, diferentemente da estrutura familiar fixa do UNIX.
Estados de processos4.1.5
Embora cada processo opere como uma entidade independente, possuindo seu próprio contador de programa e estado interno, é frequente a necessidade de interação entre eles. Um cenário comum é quando a saída de um processo serve de entrada para outro. Considere o seguinte comando shell:
cat chapter1 chapter2 chapter3 | grep tree
Neste exemplo, o primeiro processo (cat) concatena três arquivos e envia o resultado como saída. O segundo processo (grep) filtra essas informações, selecionando apenas as linhas que contêm a palavra "tree". A sincronia entre eles depende da velocidade relativa e da complexidade de cada programa. Se o grep estiver pronto para processar, mas o cat ainda não tiver enviado dados, o grep deverá ser bloqueado.
É crucial distinguir as razões pelas quais um processo para. O bloqueio lógico ocorre quando um processo não pode continuar porque aguarda um dado externo (como no exemplo acima). Já a parada por decisão do sistema ocorre quando o sistema operacional decide alocar a CPU para outro processo, mesmo que o primeiro esteja apto a continuar.
Para sistematizar essas condições, definimos três estados fundamentais em que um processo pode se encontrar:
| Estado | Descrição e Condição |
|---|---|
| Em Execução | O processo está, de fato, utilizando a CPU naquele instante. |
| Pronto | O processo é executável e está disposto a rodar, mas está temporariamente parado para dar lugar a outro. |
| Bloqueado | O processo é incapaz de ser executado até que um evento externo (como uma entrada de dados) ocorra. |
A dinâmica entre esses estados é regida por transições específicas, conforme ilustrado no diagrama de estados a seguir:
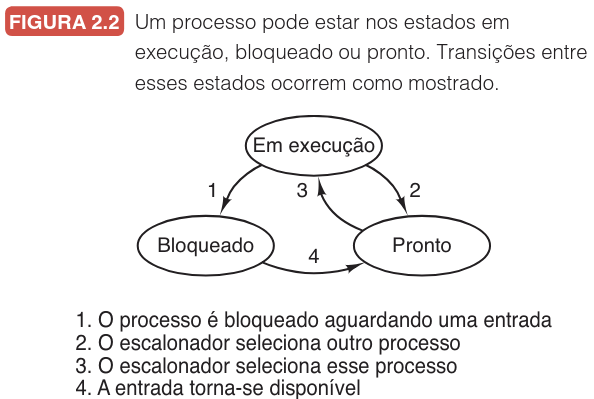
Analisando a figura acima, identificamos quatro transições possíveis, numeradas de 1 a 4, que descrevem o ciclo de vida operacional do processo:
- Bloqueio (Execução $\rightarrow$ Bloqueado): Ocorre quando o sistema operacional percebe que o processo não pode continuar imediatamente. Isso pode ser voluntário (chamada de sistema
pause) ou automático (leitura de um pipe ou terminal vazio). - Preempção (Execução $\rightarrow$ Pronto): Esta transição é causada pelo escalonador de processos. O sistema decide que o processo atual já usou a CPU por tempo suficiente e deve ceder lugar a outro.
- Seleção (Pronto $\rightarrow$ Execução): Também gerida pelo escalonador, ocorre quando chega a vez de um processo na fila "Pronto" assumir a CPU novamente.
- Desbloqueio (Bloqueado $\rightarrow$ Pronto): Acontece quando o evento externo aguardado se concretiza (ex: a entrada de dados chega). Se não houver outro processo em execução, a transição 3 pode ocorrer imediatamente após.
O escalonamento — a decisão de quem executa, quando e por quanto tempo — é vital para o equilíbrio do sistema. Algoritmos complexos são desenvolvidos para garantir tanto a eficiência global (uso da CPU) quanto a justiça individual (nenhum processo fica estagnado).
Essa abstração permite visualizar o sistema operacional em camadas. No nível mais baixo, temos o escalonador, que oculta os detalhes complexos de interrupções e gerenciamento de hardware (disco, fita, terminais). Acima dele, reside uma variedade de processos de usuário e de sistema.
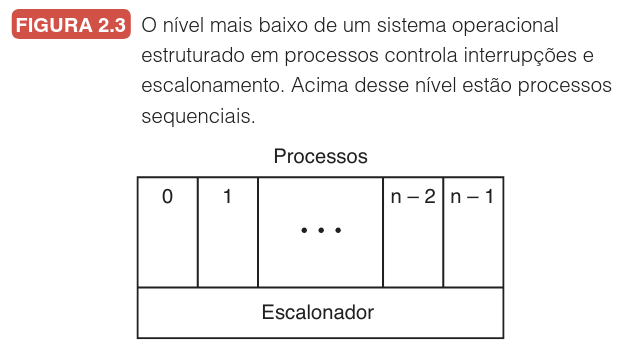
Conforme demonstrado na figura acima, quando ocorre uma interrupção (como a leitura de um disco concluída), o sistema não precisa lidar com "interrupções cruas" o tempo todo, mas sim gerenciar estados de processos. O processo que aguardava o disco (estado Bloqueado) é movido para o estado Pronto (transição 4), tornando-se elegível para execução novamente. Esse modelo transforma a complexidade do hardware em um fluxo lógico de processos bloqueando e desbloqueando.
Implementação de processos4.1.6
Para viabilizar o modelo de processos, o sistema operacional mantém uma estrutura de dados centralizada conhecida como tabela de processos, ou Bloco de Controle de Processos (PCB). Esta tabela funciona como um arranjo de registros onde cada entrada é dedicada a um processo específico, armazenando todos os dados necessários para que o sistema possa suspender sua execução e retomá-la posteriormente sem qualquer perda de continuidade.
Os campos contidos nessa tabela são vitais para a integridade do sistema, abrangendo desde o estado da CPU até o gerenciamento de recursos externos. A organização dessas informações geralmente segue três categorias principais:
| Gerenciamento de Processos | Gerenciamento de Memória | Gerenciamento de Arquivos |
|---|---|---|
| Contador de programa (PC) | Ponteiro para segmento de texto | Diretório raiz |
| Registradores e Ponteiro de pilha | Ponteiro para segmento de dados | Descritores de arquivos abertos |
| Estado do processo (Pronto, Bloqueado) | Ponteiro para segmento de pilha | IDs de usuário e grupo (UID/GID) |
| Prioridade e Parâmetros de escalonamento | Limites de memória e proteção | Atributos de permissão |
Embora os campos exatos variem entre sistemas operacionais, a Figura 2.4 ilustra os elementos universais necessários para a transparência na troca de contexto.

A ilusão de múltiplos processos executando simultaneamente em uma única CPU é sustentada por um mecanismo de hardware e software coordenado. Quando ocorre um evento de entrada ou saída, como uma interrupção de disco, o hardware consulta o vetor de interrupção, um local fixo na memória que aponta para o endereço da rotina de serviço correspondente.
O hardware realiza o salvamento inicial, empilhando o contador de programa e a palavra de estado do processo (PSW) atual. A partir desse ponto, o software assume o controle através de uma sequência rigorosa:
- Salvamento de Estado: Uma rotina em linguagem de montagem salva os registradores na entrada da tabela de processos.
- Troca de Pilha: O ponteiro de pilha é redirecionado para uma pilha temporária do sistema operacional.
- Execução em C: Uma rotina em linguagem de alto nível (C) processa a lógica específica da interrupção.
- Escalonamento: O escalonador decide qual processo deve ocupar a CPU a seguir.
- Retomada: O código em montagem carrega o estado do novo processo escolhido, reiniciando sua execução.
Este ciclo garante que, embora um processo possa ser interrompido milhares de vezes por segundo, ele sempre retorne exatamente ao estado anterior, mantendo a integridade lógica da computação. O resumo detalhado deste fluxo, desde o hardware até o escalonador, pode ser observado na Figura 2.5.
Operações de baixo nível, como a manipulação direta do ponteiro de pilha e o salvamento de registradores específicos, são executadas obrigatoriamente em linguagem de montagem, pois não podem ser expressas de forma nativa e segura em C.
Modelando a multiprogramação4.1.7
A utilização da CPU pode ser significativamente aperfeiçoada através do uso da multiprogramação. De maneira direta, se um processo médio realiza computações apenas 20% do tempo em que reside na memória, a presença de cinco processos simultâneos deveria, teoricamente, manter a CPU ocupada o tempo todo. Entretanto, esse modelo inicial é irrealisticamente otimista, pois presume tacitamente que todos os processos jamais estarão aguardando por uma entrada ou saída (E/S) ao mesmo tempo.
Um modelo mais refinado examina o uso da CPU sob um ponto de vista probabilístico. Supondo que um processo passe uma fração $p$ de seu tempo esperando pela conclusão de dispositivos de E/S, e havendo $n$ processos na memória, a probabilidade de todos os processos estarem em espera simultânea, momento em que a CPU ficaria ociosa, é $p^n$. A partir disso, a eficiência do sistema é calculada:
A utilização da CPU é dada pela fórmula: $Utilização = 1 - p^n$.
Onde n representa o grau de multiprogramação.
Este comportamento é detalhado na figura a seguir, que ilustra a utilização como uma função do número de processos:
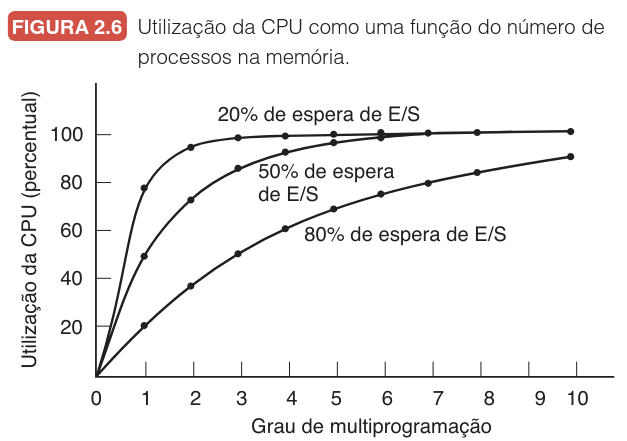
Observando os dados, fica claro que se os processos passam 80% do tempo em espera de E/S, são necessários pelo menos 10 processos na memória para que o desperdício da CPU seja inferior a 10%. É importante notar que tempos de espera de 80% ou mais são comuns, tanto em processos interativos, que aguardam cliques ou entradas de teclado, quanto em servidores que realizam intensas operações de disco.
Embora o modelo probabilístico seja uma aproximação e presuma que os processos são independentes, o que nem sempre ocorre em sistemas de CPU única onde processos prontos precisam esperar o processador ser liberado, ele ainda é válido para demonstrar como a multiprogramação ocupa a CPU em momentos de ócio. O funcionamento interno desse sistema, especialmente quando ocorrem interrupções que permitem a troca de processos, segue uma sequência rigorosa de hardware e software:
| Ordem | Etapa do Processamento de Interrupção | Descrição Técnica |
|---|---|---|
| 1 | Empilhamento de Hardware | O hardware empilha o contador de programa e outros estados essenciais. |
| 2 | Carga do Contador | O hardware carrega o novo contador de programa a partir do arranjo de interrupções. |
| 3 | Salvamento de Registradores | Um procedimento em linguagem de montagem salva o estado atual dos registradores. |
| 4 | Configuração de Pilha | Ocorre a configuração de uma nova pilha de execução para o serviço. |
| 5 | Serviço em C | O serviço de interrupção em C executa, lendo e armazenando a entrada temporariamente. |
| 6 | Escalonamento | O escalonador decide qual será o próximo processo a entrar em execução. |
| 7 | Retorno ao Assembly | O procedimento em C retorna o controle para o código de baixo nível. |
| 8 | Início do Processo | O procedimento em linguagem de montagem inicia o novo processo atual. |
Este modelo permite realizar previsões específicas sobre o desempenho. Considere um computador com 8 GB de memória, onde o sistema operacional e suas tabelas ocupam 2 GB e cada programa de usuário também ocupa 2 GB. Esta configuração permite três programas simultâneos. Com uma espera de E/S de 80%, a utilização da CPU é de $1 - 0,8^3$, aproximadamente 49%. Ao dobrar a memória para 16 GB, o grau de multiprogramação sobe para sete processos, elevando a utilização para 79%, um ganho de 30% na eficiência. Uma nova adição de 8 GB elevaria a utilização para 91%, um incremento de apenas 12%, o que permite ao gestor decidir se o investimento adicional em hardware é economicamente viável frente ao ganho marginal de desempenho.
Threads4.2
Diferente dos sistemas operacionais tradicionais, onde cada processo possui apenas um espaço de endereçamento e um único fluxo de execução, as arquiteturas modernas permitem a existência de múltiplos threads de controle compartilhando o mesmo ambiente de memória. Essa estrutura possibilita que diversas tarefas operem em quase paralelo, funcionando como processos independentes que, contudo, dividem os mesmos recursos e dados. A implementação desse modelo otimiza a performance e a organização do software, permitindo que diferentes partes de um programa executem simultaneamente sem o isolamento total imposto por processos distintos.
Utilização de threads4.2.1
Para viabilizar o modelo de processos, o sistema operacional mantém uma estrutura de dados centralizada conhecida como tabela de processos, ou Bloco de Controle de Processos (PCB), que funciona como um arranjo de registros onde cada entrada é dedicada a um processo específico. Essas entradas armazenam dados cruciais para que o sistema possa suspender a execução e retomá-la sem perda de continuidade, incluindo o contador de programa, ponteiros de pilha e o estado dos arquivos abertos. A organização dessas informações geralmente segue categorias fundamentais para a integridade do sistema, conforme detalhado na tabela abaixo:
| Gerenciamento de Processos | Gerenciamento de Memória | Gerenciamento de Arquivos |
|---|---|---|
| Contador de programa (PC) | Ponteiro para segmento de texto | Diretório raiz |
| Registradores e Pilha | Ponteiro para segmento de dados | Descritores de arquivos |
| Estado do processo | Limites de memória e proteção | Permissões (UID/GID) |
A ilusão de múltiplos processos simultâneos em uma única CPU é sustentada por um mecanismo coordenado entre hardware e software. Quando ocorre uma interrupção, como uma operação de disco, o hardware consulta o vetor de interrupção e empilha a palavra de estado do processo atual. A partir disso, uma rotina em linguagem de montagem salva os registradores na tabela de processos e configura uma pilha temporária para que o serviço de interrupção em C possa executar. Após o processamento, o escalonador decide qual será o próximo processo, e o controle retorna ao código em montagem para carregar o novo estado. Este ciclo garante que, mesmo interrompido milhares de vezes, o processo retorne ao estado preciso em que se encontrava, conforme ilustrado no esquema de fluxo abaixo:

Diferente do isolamento total dos processos, as threads surgem como "miniprocessos" que compartilham o mesmo espaço de endereçamento. Enquanto um processo tradicional tem um único thread de controle, aplicações modernas utilizam múltiplos threads para realizar atividades simultâneas de forma mais simples e rápida. Criar uma thread pode ser de 10 a 100 vezes mais veloz do que criar um processo, o que é vital quando a demanda muda dinamicamente. Um exemplo clássico é o processador de texto, que utiliza threads distintas para interagir com o usuário, reformatar o documento em segundo plano e realizar backups periódicos no disco.
Em um servidor, um thread despachante lê as requisições e as passa para threads operários ociosos. Se um operário precisa buscar algo no disco, ele é bloqueado, mas os outros continuam trabalhando, permitindo que a CPU processe outras demandas em vez de ficar ociosa.
A escolha do modelo de implementação impacta diretamente o desempenho e a facilidade de desenvolvimento. Enquanto o modelo de thread única é simples, porém lento por bloquear a CPU em cada operação de E/S, o modelo multithread retém a simplicidade das chamadas bloqueantes com alto desempenho. Existe ainda a abordagem de máquina de estados finitos, que utiliza chamadas não bloqueantes e interrupções, alcançando alta performance ao custo de uma programação extremamente complexa, onde o estado deve ser salvo manualmente a cada transição.
O uso de threads também é essencial em sistemas com múltiplas CPUs, onde o paralelismo real é atingido. Em aplicações de processamento de dados intensivo, o uso de threads de entrada, processamento e saída permite que todas as etapas ocorram simultaneamente, desde que as chamadas de sistema bloqueiem apenas a thread solicitante, preservando a execução das demais entidades dentro do mesmo processo.
O modelo de thread clássico4.2.2
O modelo de processo fundamenta-se em dois pilares independentes: o agrupamento de recursos e a execução. Enquanto os processos são utilizados para organizar recursos relacionados, como espaços de endereçamento, arquivos abertos e tratadores de sinais, as threads são as entidades efetivamente escalonadas para execução na CPU. Ao separar esses conceitos, permitimos que múltiplas linhas de execução ocorram no mesmo ambiente de maneira cooperativa, transformando o que antes era um processo pesado em uma estrutura de multithread, onde cada thread funciona como um "processo leve".
Diferente de processos independentes que compartilham recursos físicos como discos e impressoras, threads dentro de um mesmo processo compartilham o mesmo espaço de endereçamento e variáveis globais. Isso significa que não há proteção de memória entre elas: uma thread pode ler ou escrever na pilha de outra. Essa ausência de barreiras é intencional, partindo do princípio de que os threads de um mesmo usuário foram criados para colaborar em uma tarefa comum, e não para competir. A distinção visual entre processos tradicionais e um processo multithread é apresentada a seguir:
A gestão dessas entidades exige que cada thread mantenha seu próprio estado de execução para garantir a independência lógica. A tabela abaixo detalha quais itens são mantidos de forma global (por processo) e quais são estritamente individuais (por thread):
| Itens Compartilhados (Por Processo) | Itens Individuais (Por Thread) |
|---|---|
| Espaço de endereçamento e variáveis globais | Contador de programa (PC) |
| Arquivos abertos e processos filhos | Registradores da CPU |
| Alarmes e sinais pendentes | Pilha de execução (Stack) |
| Informações de contabilidade e estatísticas | Estado (Execução, Pronto, Bloqueado) |
Cada thread possui sua própria pilha, que armazena o histórico de rotinas chamadas, variáveis locais e endereços de retorno, conforme ilustrado na figura:
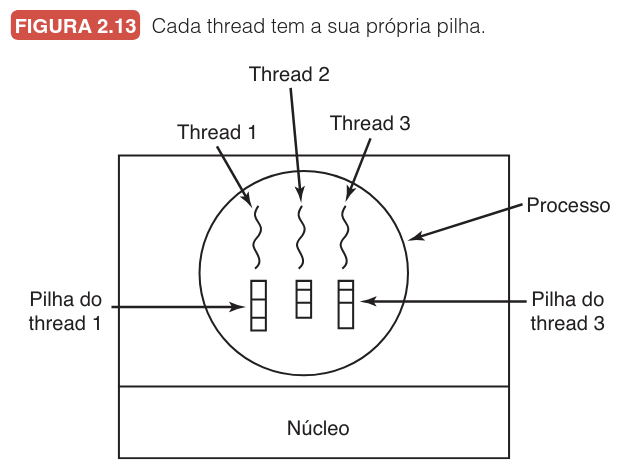
No ciclo de vida de uma aplicação multithread, o processo geralmente inicia com um único thread, que pode gerar novos fluxos através de chamadas de biblioteca como thread_create. Uma vez criados, os threads podem terminar sua execução com thread_exit ou aguardar a finalização de outros via thread_join. Um comando essencial neste modelo é o thread_yield, que permite a um thread abrir mão voluntariamente da CPU. Como muitas vezes não há uma interrupção de relógio forçada para threads como ocorre com processos, essa "cortesia" é fundamental para o paralelismo aparente em sistemas de CPU única.
O uso de threads introduz desafios significativos de projeto. Por exemplo, se um thread fecha um arquivo enquanto outro ainda realiza uma leitura, ou se dois threads tentam alocar memória simultaneamente, o sistema pode entrar em estado inconsistente. Além disso, operações como o fork em sistemas UNIX tornam-se complexas: deve o processo filho herdar todos os threads do pai ou apenas o que executou a chamada?
Em uma CPU única, o sistema alterna rapidamente entre os threads, criando a ilusão de execução paralela. Se houver três threads limitados pela CPU, cada um parecerá rodar em um processador com um terço da velocidade real. No entanto, o benefício real surge na sobreposição de tarefas de computação e E/S, onde um thread pode continuar ativo enquanto outro aguarda uma resposta do hardware.
Threads POSIX4.2.3
Para possibilitar que se escrevam programas com threads portáteis, o IEEE definiu o padrão 1003.1c, conhecido popularmente como Pthreads. A maioria dos sistemas UNIX dá suporte a este pacote, que define mais de 60 chamadas de função para gerenciar o ciclo de vida e o comportamento das threads. Cada thread no modelo POSIX possui propriedades exclusivas, incluindo um identificador, um conjunto de registradores (como o contador de programa) e uma estrutura de atributos que define o tamanho da pilha e os parâmetros de escalonamento. O gerenciamento desses fluxos é realizado através de funções fundamentais que coordenam a criação e a finalização das tarefas, conforme detalhado na tabela abaixo:
| Chamada de Thread | Descrição Técnica da Operação |
|---|---|
| Pthread_create | Cria um novo thread e retorna seu identificador, de forma análoga ao PID de um processo. |
| Pthread_exit | Conclui a execução do thread atual e libera os recursos de sua pilha. |
| Pthread_join | Bloqueia o thread chamador até que um thread específico finalize sua execução. |
| Pthread_yield | Libera voluntariamente a CPU para que outro thread possa ser executado. |
| Pthread_attr_init | Cria e inicializa uma estrutura de atributos com valores padrão para o thread. |
| Pthread_attr_destroy | Remove a estrutura de atributos da memória sem afetar os threads que já a utilizam. |
A criação de um thread com pthread_create é intencionalmente semelhante à chamada de sistema fork, servindo o identificador de thread para referenciar a entidade em outras chamadas. Uma distinção importante entre processos e threads reside na cooperação: enquanto processos são competitivos e buscam o máximo de tempo de CPU, threads de um mesmo processo são colaborativas, uma vez que são escritas pelo mesmo programador para atingir um objetivo comum. Por essa razão, a chamada pthread_yield é essencial, permitindo que um thread "educado" abra mão do processador em favor de outro. Abaixo, observa-se a lógica de implementação em C para a criação de múltiplos threads simultâneos:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#define NUMBER_OF_THREADS 10
void *print_hello_world(void *tid) {
/* Esta funcao imprime o identificador do thread e sai. */
printf("Ola mundo. Boas vindas do thread %d\n", tid);
pthread_exit(NULL);
}
int main(int argc, char *argv[]) {
pthread_t threads[NUMBER_OF_THREADS];
int status, i;
for(i=0; i < NUMBER_OF_THREADS; i++) {
printf("Metodo Main. Criando thread %d\n", i);
status = pthread_create(&threads[i], NULL, print_hello_world, (void *)i);
if (status != 0) {
printf("Erro: pthread_create retornou o codigo %d\n", status);
exit(-1);
}
}
exit(NULL);
}
No exemplo acima, o programa principal cria dez threads que anunciam sua existência. É fundamental notar que a ordem das mensagens impressas é indeterminada e pode variar a cada execução, pois depende de como o escalonador do sistema operacional distribui o tempo de CPU entre os threads prontos. Além das funções de ciclo de vida, o padrão Pthreads oferece mecanismos robustos para gerenciar atributos de prioridade e segurança, garantindo que a execução paralela seja tanto eficiente quanto previsível dentro do ambiente compartilhado do processo.
O uso de pthread_attr_init permite que o desenvolvedor ajuste finamente o comportamento de cada thread antes mesmo de sua criação, definindo, por exemplo, se o thread deve começar em um estado "destacado" (detached), onde seus recursos são reciclados automaticamente após o término sem a necessidade de um pthread_join.
Implementando threads no espaço do usuário4.2.4
Existem duas abordagens principais para a implementação de threads: no espaço do usuário e no núcleo, sendo a escolha entre elas um tema clássico na arquitetura de sistemas operacionais. Na implementação inteiramente no espaço do usuário, o núcleo desconhece a existência das threads, gerenciando o processo como se possuísse um único fluxo de execução. Esta técnica utiliza uma biblioteca de tempo de execução (runtime system) que atua como um supervisor local, gerenciando uma tabela de threads privada para cada processo. Essa tabela armazena estados vitais, como o contador de programa, registradores e ponteiro de pilha, funcionando de forma análoga à tabela de processos do núcleo, porém em um nível hierárquico superior, conforme ilustrado na figura a seguir:
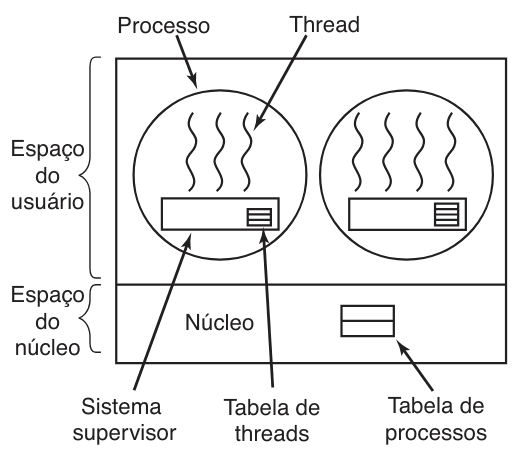
A principal vantagem deste método é a eficiência extrema no chaveamento de contexto. Como o escalonamento ocorre via chamadas de rotinas locais, não há necessidade de gerar uma armadilha (trap) para o núcleo, nem de esvaziar caches de memória ou realizar trocas de contexto pesadas no hardware. Se a CPU possuir instruções específicas para salvar e carregar registradores, a troca entre threads pode ser ordens de magnitude mais rápida do que uma chamada de sistema. Além disso, as threads de usuário permitem que cada processo adote seu próprio algoritmo de escalonamento customizado e possuem maior escalabilidade, visto que não consomem o limitado espaço de tabela do núcleo.
No entanto, essa arquitetura enfrenta obstáculos significativos, especialmente em relação às chamadas de sistema bloqueantes. Se um thread realiza uma operação de leitura de teclado e o núcleo bloqueia o processo inteiro por falta de dados, todos os outros threads daquele processo ficam paralisados, anulando um dos maiores benefícios do multithreading. Para mitigar isso, utilizam-se técnicas de verificação prévia, como o uso de códigos envolventes (jackets ou wrappers):
Para evitar o bloqueio total, a biblioteca pode substituir uma chamada de sistema read por um wrapper que utiliza a função select. Esta função verifica se a operação será bloqueada; em caso positivo, o sistema de tempo de execução suspende o thread localmente e passa a CPU para outro thread pronto, sem nunca invocar a interrupção do núcleo de forma perigosa.
Além do bloqueio por E/S, as threads de usuário sofrem com o problema das faltas de página (page faults): se uma instrução acessada não estiver na memória física, o núcleo suspende o processo completo até que o dado seja buscado no disco, ignorando que outros threads poderiam continuar executando. Outro desafio é a ausência de interrupções de relógio dentro de um processo; se um thread entra em um laço infinito ou não utiliza voluntariamente o thread_yield, ele monopoliza a CPU indefinidamente, impedindo o escalonamento circular (round-robin).
| Vantagens do Espaço do Usuário | Desvantagens do Espaço do Usuário |
|---|---|
| Alta performance no chaveamento (sem trap para o núcleo). | Uma única chamada bloqueante para o núcleo para o processo todo. |
| Portabilidade para sistemas sem suporte nativo a threads. | Faltas de página bloqueiam todos os threads do processo. |
| Escalonamento customizado por aplicação. | Necessidade de cooperação voluntária para liberar a CPU. |
| Maior escalabilidade para grandes quantidades de threads. | Dificuldade em aproveitar aplicações limitadas pela CPU. |
Por fim, o argumento mais crítico contra as threads de usuário reside na sua aplicação prática: programadores utilizam threads justamente em softwares que realizam E/S frequente, como servidores web. Se o sistema exige verificações constantes e complexas para evitar bloqueios, muitas vezes torna-se mais eficiente delegar essa gestão diretamente ao núcleo, que já possui o controle natural sobre as interrupções de hardware e o estado dos processos.
Implementando threads no núcleo4.2.5
Diferente do modelo anterior, na implementação de threads no núcleo, o sistema operacional tem plena ciência da existência de cada thread e as gerencia diretamente. Nessa arquitetura, não é necessário um sistema de tempo de execução (runtime) em cada processo, nem uma tabela de threads privada no espaço do usuário. Em vez disso, o núcleo mantém uma tabela mestre que controla todos os threads do sistema, conforme ilustrado na figura a seguir:
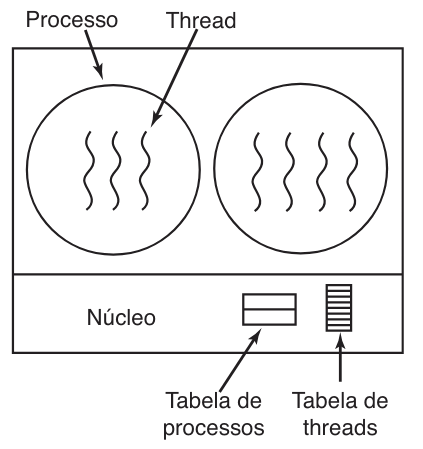
Quando um thread precisa ser criado ou destruído, o processo realiza uma chamada de sistema (trap) para o núcleo, que atualiza sua tabela interna. Esta tabela armazena os registradores, o estado e o contexto de cada thread, funcionando como um subconjunto das informações que o núcleo já mantém na tabela de processos tradicional. A principal vantagem dessa abordagem é a capacidade de resposta a eventos de bloqueio:
- Gerenciamento de Bloqueio: Se um thread realiza uma chamada de sistema bloqueante, o núcleo pode suspender esse thread e escolher imediatamente outro thread do mesmo processo (ou de um processo diferente) para executar.
- Tratamento de Faltas de Página: Caso um thread cause uma falta de página (page fault), o núcleo não bloqueia o processo inteiro. Ele pode verificar se existem outros threads executáveis no mesmo processo e escaloná-los enquanto a página é buscada no disco.
Devido ao custo mais elevado de criação e destruição no nível do núcleo, muitos sistemas utilizam a técnica de reciclagem. Em vez de descartar as estruturas de dados quando um thread termina, o núcleo apenas o marca como não executável. Quando um novo thread é solicitado, a estrutura antiga é reativada, economizando tempo de processamento.
Embora resolva problemas de bloqueio e não exija chamadas não bloqueantes complexas, o modelo de núcleo possui desvantagens significativas em termos de desempenho. Cada operação de thread (criação, término ou sincronização) exige uma chamada de sistema, que é consideravelmente mais cara do que uma simples chamada de biblioteca no espaço do usuário. Além disso, problemas lógicos complexos permanecem, conforme detalhado na tabela abaixo:
| Problema de Projeto | Descrição da Complicação |
|---|---|
| Bifurcação (Fork) | Se um processo com 10 threads é bifurcado, o novo processo deve herdar todos os 10 ou apenas um? A resposta depende se o novo processo executará um novo programa (exec) ou continuará o código atual. |
| Gerenciamento de Sinais | Sinais são enviados ao processo. O núcleo deve decidir qual thread específico receberá o sinal ou se todos devem ser notificados simultaneamente. |
| Sobrecarga (Overhead) | O custo de mudar o contexto entre threads exige a troca de privilégio para o modo núcleo, o que consome mais ciclos de CPU. |
Dessa forma, a implementação no núcleo oferece maior robustez e paralelismo real para aplicações com muita E/S, mas exige que o programador e o arquiteto de sistemas ponderem o custo das chamadas de sistema frequentes.
Implementações híbridas4.2.6
Diversas arquiteturas foram investigadas com o objetivo de unir a alta performance das threads de usuário à robustez e ao paralelismo das threads de núcleo. A solução mais proeminente é o modelo híbrido, que utiliza threads de núcleo como unidades de execução base e multiplexa threads de usuário sobre elas. Essa abordagem permite que o programador determine de forma flexível a proporção entre threads de núcleo e threads de usuário, otimizando o sistema conforme a necessidade da aplicação.
Neste modelo, o núcleo do sistema operacional enxerga e escalona apenas as threads de núcleo. Sobre cada uma delas, podem existir múltiplas threads de usuário que são criadas, destruídas e escalonadas por um sistema de tempo de execução local, operando de forma idêntica ao modelo de espaço de usuário puro. Cada thread de núcleo atua como uma "CPU virtual" para um conjunto específico de threads de usuário que se revezam para utilizá-la.
A tabela a seguir resume como as responsabilidades são divididas e os benefícios gerados por essa arquitetura:
| Componente | Função no Modelo Híbrido | Vantagem Proporcionada |
|---|---|---|
| Threads de Núcleo | Servem como portadores físicos para a execução e lidam com bloqueios de E/S. | Se uma thread bloqueia, o núcleo pode escalonar outra thread de núcleo para manter o processo ativo. |
| Threads de Usuário | Gerenciadas pela biblioteca da aplicação para tarefas leves e rápidas. | Permite a criação de milhares de fluxos de controle com baixíssimo custo de memória e processamento. |
| Multiplexação | Associa dinamicamente threads de usuário às threads de núcleo disponíveis. | Proporciona flexibilidade máxima, permitindo o paralelismo real em máquinas multiprocessadas. |
Este modelo, às vezes chamado de modelo m:n, permite que o desenvolvedor tenha o melhor de dois mundos: o chaveamento instantâneo entre threads de usuário quando não há bloqueios e a garantia de que o processo não paralisará completamente quando uma operação de sistema for necessária.
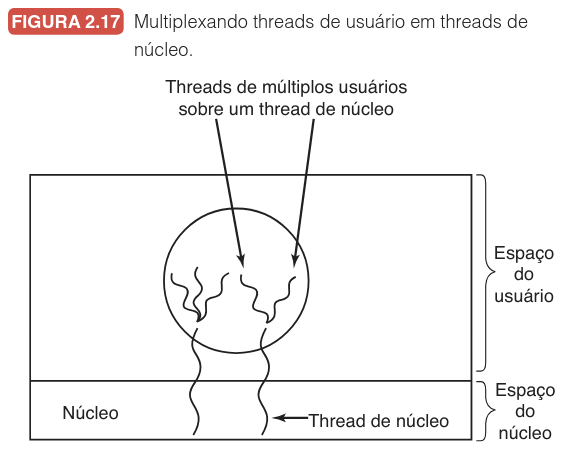
Dessa forma, as implementações híbridas eliminam a rigidez dos modelos puros. Se uma aplicação possui muitas tarefas pequenas e rápidas, ela pode usar poucas threads de núcleo para muitas de usuário; se a aplicação exige muita comunicação com o hardware, a proporção pode ser ajustada para garantir que sempre haja um caminho de execução disponível no núcleo.
Ativações pelo escalonador4.2.7
As ativações pelo escalonador surgem como uma proposta para unificar a eficiência das threads de usuário com a funcionalidade robusta das threads de núcleo. O objetivo central é permitir que um processo gerencie suas próprias threads no espaço do usuário, mas mantenha a capacidade de reagir a eventos de bloqueio (como faltas de página ou chamadas de sistema) sem paralisar o processo inteiro. Para isso, o núcleo delega a execução a "processadores virtuais", permitindo que o sistema de tempo de execução aloque threads para eles de forma dinâmica e independente.
O diferencial técnico desta abordagem é a inversão do fluxo de comunicação tradicional através de um mecanismo chamado upcall. Em sistemas convencionais, o espaço do usuário solicita serviços ao núcleo; nas ativações pelo escalonador, o núcleo toma a iniciativa de notificar o sistema de tempo de execução sobre eventos relevantes. Este fluxo operacional segue uma lógica específica:
- Bloqueio e Notificação: Quando um thread é bloqueado (por uma chamada de sistema ou falta de página), o núcleo interrompe a execução e "sobe" para o espaço do usuário, ativando o sistema de tempo de execução em um endereço conhecido.
- Transferência de Contexto: O núcleo passa para a pilha do sistema de tempo de execução o número do thread afetado e a descrição do evento.
- Reescalonamento Local: O sistema de tempo de execução marca o thread como bloqueado e imediatamente coloca outro thread pronto para rodar no processador virtual disponível.
- Notificação de Desbloqueio: Assim que a causa do bloqueio é resolvida (ex: o dado chegou do disco), o núcleo realiza um novo upcall, informando que o thread original pode ser reiniciado ou colocado na lista de prontos.
Uma crítica comum a este modelo é que o uso de upcalls viola o princípio de design de sistemas em camadas. Tradicionalmente, camadas superiores chamam as inferiores, mas as inferiores nunca deveriam invocar rotinas nas superiores. O upcall quebra essa hierarquia ao fazer o núcleo (camada inferior) chamar o espaço do usuário (camada superior).
A eficiência desse modelo reside na redução de transições desnecessárias entre os modos de operação. Se um thread precisa esperar por outro dentro do mesmo processo, o sistema de tempo de execução resolve a sincronização internamente, sem qualquer intervenção do núcleo. Caso ocorra uma interrupção de hardware que interesse ao processo, o núcleo suspende o thread atual e inicia o sistema de tempo de execução naquela CPU virtual, permitindo que a própria aplicação decida qual thread é prioritário no momento.
| Característica | Threads de Usuário Puras | Threads de Núcleo Puras | Ativações pelo Escalonador |
|---|---|---|---|
| Desempenho | Altíssimo (local) | Lento (chamada de sistema) | Alto (híbrido) |
| Bloqueio de E/S | Bloqueia o processo todo | Bloqueia apenas o thread | Bloqueia apenas o thread |
| Falta de Página | Para o processo todo | Gerenciada pelo núcleo | Gerenciada via Upcall |
| Complexidade | Baixa | Média | Alta (exige upcalls) |
Este mecanismo oferece o máximo de flexibilidade em sistemas multiprocessados, onde o número de CPUs virtuais pode ser ajustado conforme a carga de trabalho do processo. Apesar da complexidade de implementação, o ganho de desempenho em aplicações que realizam muitas operações de entrada e saída é considerável.
Threads pop-up4.2.8
Em sistemas distribuídos, a eficiência no tratamento de mensagens e requisições de serviço é vital. A abordagem convencional utiliza um processo ou thread permanentemente bloqueado em uma chamada de sistema receive, aguardando a chegada de dados. No entanto, uma alternativa altamente eficiente para reduzir a latência de processamento é o uso de threads pop-up, onde a própria chegada de uma mensagem dispara a criação imediata de um novo fluxo de execução.
Diferente das threads tradicionais, uma thread pop-up não possui histórico prévio, como estados de registradores ou pilhas que precisem ser restaurados. Cada thread "nasce" limpa e idêntica às demais, o que permite que o sistema a instancie com velocidade máxima para processar a mensagem recém-chegada. O ciclo de criação é ilustrado a seguir:
A utilização desta técnica exige decisões arquiteturais estratégicas, especialmente sobre o contexto de execução da thread. A tabela abaixo compara as implicações de executar threads pop-up em diferentes espaços:
| Contexto de Execução | Vantagens | Riscos e Desvantagens |
|---|---|---|
| Espaço do Núcleo (Kernel) | Acesso direto a tabelas do sistema e dispositivos de E/S; criação mais rápida. | Um erro no código da thread (ex: laço infinito) pode comprometer todo o sistema ou causar perda de dados. |
| Espaço do Usuário | Maior segurança e isolamento; erros na thread não derrubam o núcleo. | Ligeiramente mais lento devido à necessidade de troca de contexto e proteção de memória. |
O principal benefício da thread pop-up é o encurtamento do tempo entre a recepção física do pacote na rede e o início do seu processamento lógico, uma vez que não há necessidade de despertar e restaurar o contexto de uma thread pré-existente que estava "dormindo".
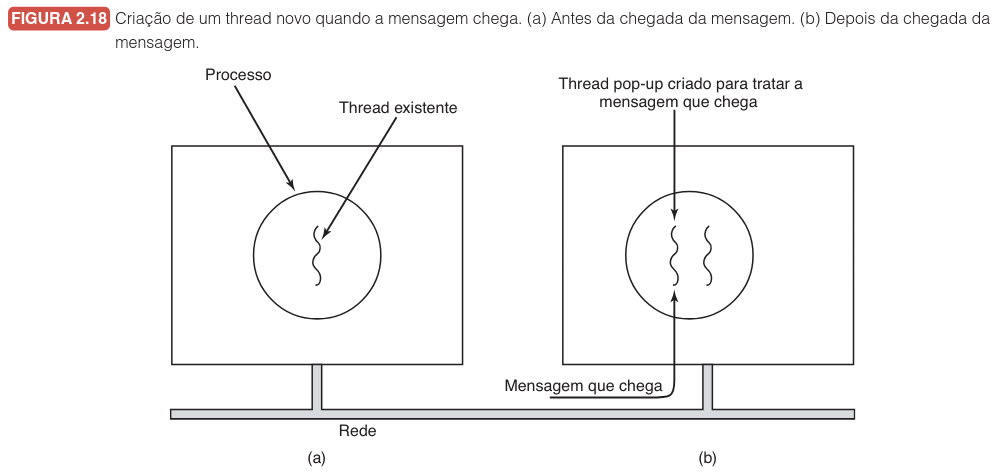
Embora poderosas, as threads pop-up demandam um planejamento rigoroso. Como elas operam frequentemente em ambientes de alta concorrência e podem ser executadas no núcleo, é fundamental garantir que o código de tratamento seja conciso e libere a CPU rapidamente para evitar gargalos no recebimento de novas mensagens.
Convertendo código de um thread em código multithread4.2.9
A transição de programas concebidos para processos monothread para o modelo de múltiplas threads é uma tarefa consideravelmente complexa, pois envolve armadilhas que podem comprometer a integridade de dados compartilhados. O problema fundamental reside na coexistência de rotinas que utilizam recursos globais em um mesmo espaço de endereçamento. Um exemplo crítico ocorre com variáveis globais do sistema, como a errno do UNIX, utilizada para reportar erros de chamadas de sistema. Em um cenário multithread, se um thread executa uma operação que falha e, antes de ler o código de erro, ocorre um chaveamento para um segundo thread que também falha, o valor original de errno será sobrescrito, levando o primeiro thread a um comportamento incorreto ao retomar sua execução.
Para solucionar conflitos de variáveis globais, uma abordagem eficaz é a criação de variáveis globais privadas por thread, conhecidas como Thread-Local Storage (TLS). Isso estabelece um novo nível de escopo: variáveis visíveis para todas as funções de um thread específico, mas isoladas dos demais fluxos, conforme ilustrado na organização de pilhas e memórias globais abaixo:

Além do isolamento de variáveis, a conversão enfrenta o desafio das bibliotecas não reentrantes. Muitas rotinas de biblioteca padrão, como o malloc para alocação de memória ou funções de buffer de rede, não foram projetadas para serem chamadas simultaneamente. Se um thread for interrompido enquanto o malloc está atualizando listas encadeadas de memória, deixando-as em um estado inconsistente, e um segundo thread tentar alocar memória, o programa poderá falhar devido ao uso de ponteiros inválidos. Consertar esses problemas exige a reescrita de bibliotecas inteiras para torná-las seguras para threads (thread-safe), ou a implementação de "proteções" (locks) que restringem o acesso às funções, embora esta última solução reduza significativamente o paralelismo potencial do sistema.
Sinais e pilhas representam uma complicação adicional. Sinais específicos, como alarm, deveriam ser direcionados ao thread solicitante, mas o núcleo pode não ter ciência da existência das threads para realizar esse direcionamento. Da mesma forma, o crescimento automático da pilha, realizado pelo núcleo em processos tradicionais, torna-se problemático quando existem múltiplas pilhas no mesmo processo que o núcleo não reconhece individualmente.
Em suma, a implementação de threads em sistemas existentes requer alterações substanciais que vão além da simples criação de novos fluxos de execução. É necessário redefinir a semântica de chamadas de sistema e garantir que bibliotecas e tratadores de sinais operem de forma previsível no ambiente compartilhado. A compatibilidade com programas legados monothread deve ser mantida como um caso limite, assegurando que o sistema permaneça funcional e estável mesmo sob estas novas demandas de concorrência.
Questões4.3
1. O texto introduz o conceito de "pseudoparalelismo" em contraste com o "verdadeiro paralelismo". Com base nessa distinção e na definição de processo, assinale a alternativa correta:
- A) O pseudoparalelismo ocorre apenas em sistemas multicore, onde cada núcleo executa um processo distinto simultaneamente.
- B) Um processo é uma entidade passiva, análoga a uma receita de bolo, enquanto o programa é a entidade ativa, análoga ao cozinheiro.
- C) O verdadeiro paralelismo refere-se à alternância rápida da CPU entre processos, criando a ilusão de que múltiplos programas rodam ao mesmo tempo.
- D) O pseudoparalelismo é a ilusão de simultaneidade criada por uma única CPU que alterna entre processos em intervalos de milissegundos.
2. Considere o modelo probabilístico de utilização da CPU apresentado, onde a utilização é dada pela fórmula $U = 1 - p^n$. Suponha um sistema operacional que gerencie processos com diferentes características de entrada e saída (E/S). Realize os cálculos abaixo:
- a) Se um processo gasta 50% ($p=0,5$) do seu tempo esperando por E/S, qual é a utilização da CPU se houver 4 processos ($n=4$) na memória?
- b) Se aumentarmos o grau de multiprogramação para 10 processos ($n=10$) com o mesmo tempo de espera de 50%, qual será a nova utilização da CPU? (Considere $0,5^{10} \approx 0,001$).
- c) Considere agora processos pesados de E/S que esperam 80% do tempo ($p=0,8$). Calcule a utilização da CPU com 5 processos simultâneos.
- d) Para os mesmos processos do item 'c' ($p=0,8$), quantos processos (n) são necessários, no mínimo, para garantir que a CPU fique ociosa menos de 10% do tempo? (Dica: Analise o gráfico da Figura 2.6 ou teste valores inteiros para $n$).
- e) Explique, com base nos resultados acima, por que adicionar memória RAM (permitindo maior grau de multiprogramação) traz retornos decrescentes de performance à medida que a utilização se aproxima de 100%.
3. Acerca do diagrama de estados de processos e as transições numeradas. Relacione a transição descrita na Coluna A com a causa técnica correta na Coluna B.
| Coluna A (Transição) | Coluna B (Causa Técnica) |
|---|---|
| (1) Execução $\rightarrow$ Bloqueado | ( ) O escalonador decide que o processo atual usou tempo suficiente de CPU e deve ceder lugar. |
| (2) Execução $\rightarrow$ Pronto | ( ) O evento externo aguardado se concretiza (ex: chegada de dados do disco), tornando o processo apto a rodar. |
| (3) Pronto $\rightarrow$ Execução | ( ) O sistema operacional seleciona este processo da fila para ocupar a CPU. |
| (4) Bloqueado $\rightarrow$ Pronto | ( ) O processo executa uma chamada de sistema (como pause ou leitura de pipe vazio) e não pode continuar imediatamente. |
4. Sobre a implementação de threads e a distinção entre itens compartilhados e privados, classifique os elementos abaixo. Marque (P) para itens exclusivos de cada Thread e (C) para itens Compartilhados por todo o processo.
- ( ) Espaço de endereçamento.
- ( ) Contador de Programa (PC).
- ( ) Arquivos abertos.
- ( ) Pilha de execução (Stack).
- ( ) Variáveis globais.
- ( ) Registradores da CPU.
5. A criação de processos difere significativamente entre os sistemas UNIX e Windows. Sobre essas diferenças hierárquicas e de implementação, é correto afirmar:
- A) No UNIX, a chamada
forkcria um processo filho que compartilha o mesmo espaço de endereçamento do pai para escrita, sem necessidade de cópia (copy-on-write). - B) No Windows, existe uma hierarquia rígida onde o pai nunca perde o controle sobre o filho, assemelhando-se a uma árvore genealógica fixa.
- C) No UNIX, todos os processos pertencem a uma árvore única enraizada no processo init, e um pai não pode deserdar seus filhos.
- D) No Windows, a criação de processos é feita em dois passos (criar e carregar), enquanto no UNIX a função
CreateProcessrealiza tudo em uma única chamada.
6. O texto descreve a sequência exata de eventos de hardware e software necessária para lidar com uma interrupção e realizar a troca de processos. Ordene cronologicamente os passos abaixo, do momento da interrupção até a retomada da execução:
- ( ) O escalonador escolhe o próximo processo a ser executado.
- ( ) O hardware empilha o contador de programa (PC) e a palavra de estado (PSW).
- ( ) Uma rotina em linguagem de montagem salva os registradores gerais na tabela de processos.
- ( ) O procedimento em C executa o serviço da interrupção (ex: leitura de dados).
- ( ) A rotina em linguagem de montagem carrega os registradores e o estado do novo processo escolhido.
7. Compare as implementações de threads no Espaço do Usuário versus Espaço do Núcleo. Assinale a alternativa que descreve corretamente uma vantagem ou desvantagem exclusiva do modelo citado:
- A) Espaço do Usuário: Vantagem de permitir que uma única chamada de sistema bloqueante (ex: leitura de teclado) paralise apenas a thread solicitante, e não o processo todo.
- B) Espaço do Núcleo: Desvantagem de ter um alto custo de desempenho para criação e destruição de threads devido à necessidade de chamadas de sistema (traps).
- C) Espaço do Usuário: Desvantagem de exigir traps para o núcleo a cada troca de contexto entre threads, tornando o chaveamento lento.
- D) Espaço do Núcleo: Vantagem de permitir escalonamento customizado por aplicação, já que o núcleo não interfere na política de threads.
8. O mecanismo de "Ativações pelo Escalonador" tenta unir o melhor dos mundos (usuário e núcleo) utilizando Upcalls. Explique o que é um Upcall, qual regra de hierarquia de camadas ele viola segundo o texto, e como ele ajuda a resolver o problema de bloqueio em threads de usuário.
9. Sobre as Threads Pop-up em sistemas distribuídos, marque Verdadeiro (V) ou Falso (F):
- ( ) O principal objetivo das threads pop-up é reduzir a latência entre a chegada de uma mensagem e o início do seu processamento.
- ( ) Threads pop-up possuem um histórico de execução complexo que deve ser restaurado antes de processarem a mensagem.
- ( ) Elas podem ser executadas tanto no espaço do núcleo (para maior velocidade e acesso direto) quanto no espaço do usuário (para maior segurança).
- ( ) A criação de uma thread pop-up é mais lenta do que acordar uma thread bloqueada existente, devido à necessidade de alocar nova memória.
10. A conversão de código monothread para multithread introduz desafios como o tratamento de variáveis globais (ex: errno). O texto menciona uma solução chamada TLS (Thread-Local Storage). O que essa técnica realiza?
- A) Torna todas as variáveis globais visíveis apenas para o processo pai.
- B) Bloqueia o acesso a variáveis globais usando semáforos para evitar condições de corrida.
- C) Cria variáveis que são globais para as funções dentro de um thread específico, mas privadas em relação aos outros threads.
- D) Move todas as variáveis globais para a pilha do núcleo, protegendo-as contra escrita.
Próximos passos4.4
Na próxima aula, Comunicação entre Processos, aprofundaremos a discussão sobre como processos e threads interagem em um ambiente concorrente. O foco deixará de ser apenas a estrutura interna (como são criados ou escalonados) para abordar os perigos do compartilhamento de dados. Estudaremos as condições de corrida, onde a ordem de execução altera o resultado final, e as soluções clássicas para garantir a exclusão mútua, como semáforos, monitores e troca de mensagens, essenciais para evitar o caos em sistemas operacionais.