Introdução3.1
Os sistemas operacionais evoluíram drasticamente ao longo de mais de cinco décadas, resultando em uma linhagem tecnológica vasta e heterogênea, onde nem todos os modelos desenvolvidos alcançaram o mainstream, mas cada um contribuiu para o estado da arte atual. Esta seção analisa brevemente nove variantes fundamentais, desde arquiteturas robustas para mainframes até microkernels para dispositivos vestíveis, estabelecendo uma base conceitual que será revisitada e aprofundada em discussões futuras, permitindo uma compreensão clara de como o software de base se adapta a diferentes restrições de hardware e exigências de processamento.
Sistemas operacionais de computadores de grande porte3.1.1
No topo da hierarquia de infraestrutura de TI encontram-se os sistemas operacionais projetados para computadores de grande porte, conhecidos como mainframes. Essas máquinas, ainda onipresentes em centros de processamento de dados de grandes corporações, diferenciam-se drasticamente dos computadores pessoais pela sua massiva capacidade de Entrada e Saída (E/S). É comum que um único mainframe gerencie milhares de discos e volumes de dados na escala de milhões de gigabytes, um desempenho essencial para sua atuação contemporânea como servidores sofisticados em comércio eletrônico de larga escala e transações entre empresas (B2B).
Esses sistemas são intensamente orientados para o processamento simultâneo de múltiplas tarefas e oferecem, geralmente, três modalidades de serviços fundamentais para operações críticas:
| Modalidade de Serviço | Características e Aplicações |
|---|---|
| Processamento em Lote (Batch) | Executa tarefas rotineiras de forma automática, sem a presença de um usuário interativo. Exemplos incluem o processamento de apólices de seguros ou a geração de relatórios de vendas. |
| Processamento de Transações | Gerencia um grande volume de pequenas requisições, lidando com centenas ou milhares de operações por segundo. É vital para compensação de cheques bancários ou sistemas de reservas aéreas. |
| Tempo Compartilhado (Timesharing) | Permite que múltiplos usuários remotos executem tarefas no computador simultaneamente, como na realização de consultas a um grande banco de dados centralizado. |
Muitas vezes, esses sistemas operacionais executam todas as funções acima de maneira integrada. Um exemplo clássico é o OS/390, descendente do histórico OS/360. No entanto, observa-se uma transição gradual no mercado, onde esses sistemas proprietários estão sendo substituídos por variantes UNIX, com destaque para o Linux.
Sistemas operacionais de computadores pessoais3.1.2
A categoria de sistemas operacionais voltados para computadores pessoais representa a interface mais comum da tecnologia no cotidiano. Atualmente, todos os computadores modernos oferecem suporte nativo à multiprogramação, sendo capazes de carregar e gerenciar dezenas de programas simultaneamente logo no momento da inicialização.
O objetivo primordial desses sistemas é fornecer suporte robusto e intuitivo para um único usuário, facilitando a execução de tarefas essenciais como processamento de texto, edição de planilhas e navegação na internet. A onipresença desses softwares é tão marcante que, frequentemente, o público geral desconhece a existência de outros tipos de sistemas computacionais.
A literatura técnica destaca os seguintes sistemas como representantes clássicos desta categoria:
- Base Unix/BSD: Linux, FreeBSD e OS X (Apple).
- Base Windows: Windows 7 e Windows 8.
Sistemas operacionais de tempo real3.1.3
Os sistemas operacionais de tempo real definem-se fundamentalmente pelo tratamento do tempo como um parâmetro-chave, sendo essenciais em ambientes onde a precisão temporal dita o sucesso ou o fracasso da operação. Em contextos industriais, por exemplo, computadores monitoram processos de produção e controlam o maquinário com base em prazos rígidos. A sincronia é tão vital que, em uma linha de montagem automotiva, se um robô de soldagem atuar alguns milissegundos antes ou depois do momento programado, o produto será arruinado.
A classificação desses sistemas depende da tolerância a falhas temporais, dividindo-se em críticos e não críticos, conforme detalhado na tabela a seguir:
| Categoria | Definição e Consequências | Exemplos Típicos |
|---|---|---|
| Tempo Real Crítico (Hard) | Exige garantias absolutas de que uma ação ocorrerá em um instante exato. O descumprimento de prazos pode causar danos permanentes ou falhas catastróficas. | Controle de processos industriais, aviônica, sistemas militares. |
| Tempo Real Não Crítico (Soft) | A perda ocasional de um prazo, embora indesejável, é aceitável e não resulta em danos permanentes. | Sistemas de multimídia, áudio digital, smartphones. |
Para garantir o cumprimento estrito de prazos nos sistemas críticos, o sistema operacional muitas vezes funciona apenas como uma biblioteca conectada diretamente aos programas aplicativos, como ocorre no sistema eCos. Nessa arquitetura, todas as partes do sistema estão estreitamente acopladas e sem proteção entre si, visando maximizar a velocidade de resposta.
Existe uma sobreposição funcional considerável entre as categorias de sistemas portáteis, embarcados e de tempo real, visto que quase todos possuem algum aspecto de temporalidade. Uma diferença marcante reside no público e na segurança: enquanto sistemas portáteis e embarcados focam no consumidor final, os de tempo real voltam-se para o uso industrial. Além disso, em sistemas de tempo real e embarcados, o usuário geralmente não tem permissão para adicionar softwares próprios, limitando-se aos programas inseridos pelos projetistas, o que facilita significativamente a proteção e a estabilidade do sistema.
Conceitos de sistemas operacionais3.2
A compreensão da arquitetura de sistemas operacionais exige o domínio de certas abstrações basilares fornecidas pelo software de sistema, sendo as mais críticas os processos, os espaços de endereçamento e os arquivos. Estas estruturas formam o vocabulário essencial para o gerenciamento de recursos e, embora utilizaremos exemplos práticos extraídos predominantemente do ambiente UNIX para ilustrar esses mecanismos, é crucial notar que implementações análogas sustentam o funcionamento da vasta maioria das plataformas computacionais modernas.
Processos3.2.1
O conceito de processo é a pedra angular de todos os sistemas operacionais, podendo ser definido essencialmente como um programa em execução. Todo processo funciona como um contêiner que agrupa as informações vitais para a sua operação, sendo composto por um espaço de endereçamento (uma faixa de memória que contém o programa executável, seus dados e a pilha) e um conjunto de recursos (registradores, contador de programa, ponteiro de pilha, lista de arquivos abertos e alarmes pendentes).
Para compreender intuitivamente essa dinâmica, basta observar um sistema de multiprogramação moderno. Um usuário pode, simultaneamente, renderizar um vídeo, navegar na web e receber e-mails em segundo plano. O sistema operacional alterna periodicamente entre esses processos ativos (editor de vídeo, navegador e cliente de e-mail), decidindo qual deles deve utilizar a CPU em determinado momento. Quando um processo é suspenso para dar lugar a outro, é imperativo que ele possa ser reiniciado posteriormente no exato estado em que parou.
Para viabilizar a alternância entre tarefas, o sistema armazena todas as informações do processo (exceto o conteúdo do espaço de endereçamento) em uma estrutura conhecida como Tabela de Processos. Cada entrada nessa tabela guarda o estado dos registradores, ponteiros de arquivos e outros dados críticos, garantindo que chamadas de leitura ou escrita continuem corretamente após a retomada. Assim, um processo suspenso consiste em sua imagem do núcleo (espaço de endereçamento) e sua entrada na tabela de processos.
As chamadas de sistema gerenciam o ciclo de vida desses processos, desde a criação até o término. Um exemplo clássico ocorre no shell (interpretador de comandos): quando um usuário solicita a compilação de um programa, o shell cria um novo processo filho para executar o compilador. Como processos podem criar outros processos recursivamente, forma-se uma hierarquia estrutural, conforme ilustrado abaixo:
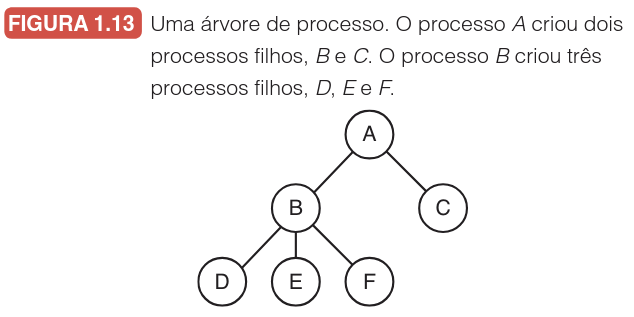
Além da criação e gerenciamento de memória, os processos precisam se comunicar e lidar com eventos assíncronos. Para isso, utilizam-se temporizadores e sinais, que são análogos em software às interrupções de hardware. Se um processo precisa retransmitir uma mensagem perdida na rede após um tempo limite, o sistema operacional envia um sinal de alarme, forçando o processo a pausar sua atividade atual, salvar seu estado e executar uma rotina de tratamento específica antes de retomar.
Por fim, a segurança e a propriedade dos processos são geridas através de identificadores atribuídos pelo administrador do sistema. A tabela a seguir resume as principais categorias de identificação e permissão:
| Identificador | Sigla | Descrição |
|---|---|---|
| Identificação do Usuário | UID | Atribuída a cada pessoa autorizada. Todo processo herda a UID de quem o iniciou (incluindo processos filhos). |
| Identificação do Grupo | GID | Permite associar usuários a grupos específicos para gestão coletiva de permissões. |
| Superusuário / Administrador | Root | Possui uma UID especial com poderes para sobrepor regras de proteção e acessar qualquer recurso do sistema. |
Espaços de endereçamento3.2.2
A memória principal é um recurso fundamental em qualquer computador, sendo o local onde os programas em execução são armazenados. Em sistemas operacionais mais rudimentares, a gestão dessa memória é simples, permitindo a execução de apenas um programa por vez. Para que um segundo software seja executado, o primeiro deve ser removido, liberando o espaço físico para o próximo ocupante.
Contudo, os sistemas operacionais modernos e sofisticados suportam a multiprogramação, permitindo que múltiplos programas residam na memória simultaneamente. Essa convivência exige mecanismos de proteção robustos para evitar que um processo interfira nos dados de outro ou desestabilize o próprio sistema operacional. Embora a implementação dessa proteção ocorra no nível do hardware, seu controle e gerenciamento são responsabilidades exclusivas do sistema operacional.
A distinção entre a memória física e a abstração lógica é crucial, conforme detalhado na tabela a seguir:
| Conceito | Definição |
|---|---|
| Memória Principal (Física) | O hardware real disponível para armazenamento volátil de dados. |
| Espaço de Endereçamento | O conjunto de endereços lógicos que um processo pode utilizar, variando de 0 até um valor máximo definido. |
O gerenciamento torna-se complexo quando consideramos arquiteturas modernas de 32 ou 64 bits. Nesses casos, o espaço de endereçamento potencial chega a $2^{32}$ ou $2^{64}$ bytes, respectivamente. Frequentemente, esse espaço lógico excede a quantidade de memória física instalada na máquina.
Historicamente, essa discrepância impedia a execução de programas maiores que a memória física. Atualmente, solucionamos esse problema através da técnica de Memória Virtual. O sistema operacional mantém apenas parte do espaço de endereçamento na memória principal (RAM) e o restante no disco, realizando a troca (swapping) de trechos de dados conforme a necessidade do processamento.
Na essência, o sistema operacional cria uma abstração onde o espaço de endereçamento é desacoplado da memória física. Isso permite que um programa utilize um espaço de memória maior do que o hardware fisicamente possui, delegando ao sistema a complexidade de gerenciar o fluxo de dados entre o disco e a RAM.
Arquivos3.2.3
Um conceito fundamental, suportado por virtualmente todos os sistemas operacionais, é o sistema de arquivos. Uma função primordial do sistema operacional consiste em ocultar as peculiaridades dos discos e outros dispositivos de E/S, apresentando ao programador um modelo agradável e claro de arquivos independentes do dispositivo. Para manipular esses arquivos, chamadas de sistema são necessárias para criar, remover, ler e escrever. Antes que um arquivo possa ser lido, ele deve ser localizado no disco e aberto; após a leitura, deve ser fechado.
Para fornecer um local para manter os arquivos, a maioria dos sistemas operacionais de computadores pessoais utiliza o conceito de diretório como uma forma de agrupamento. Um usuário pode ter diretórios distintos para cursos, correio eletrônico ou páginas da web. As chamadas de sistema permitem criar e remover diretórios, bem como adicionar ou excluir arquivos existentes dentro deles. Como as entradas de diretório podem ser arquivos ou outros diretórios, esse modelo dá origem a uma hierarquia, o sistema de arquivos, conforme ilustrado na figura a seguir:
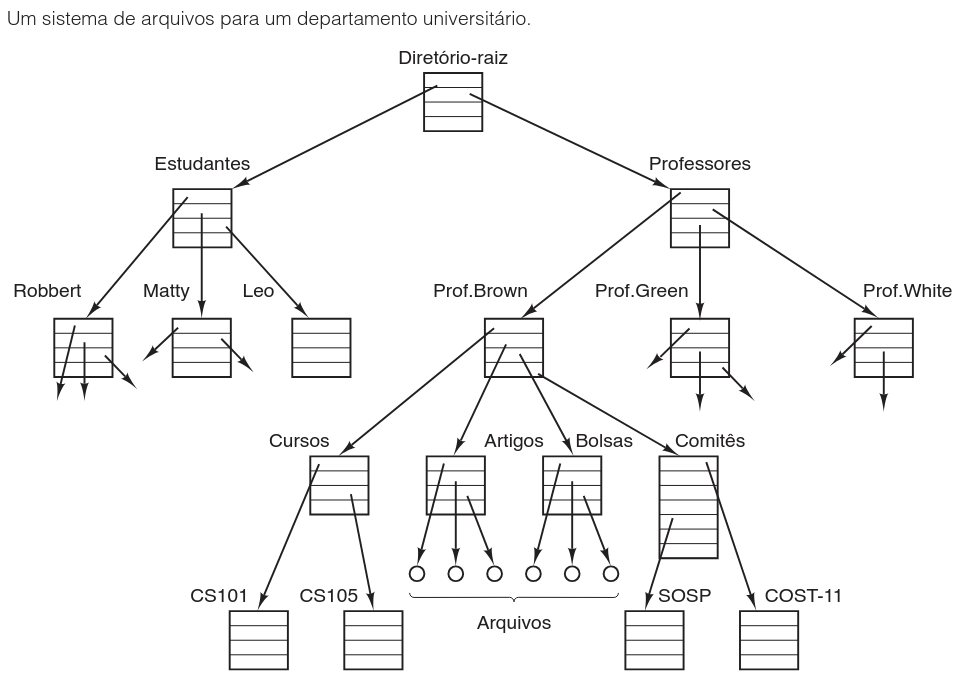
Embora ambas as hierarquias (processos e arquivos) sejam organizadas como árvores, as semelhanças encerram-se nesse ponto. Existem diferenças estruturais e funcionais significativas entre elas, detalhadas na tabela abaixo:
| Característica | Hierarquia de Processos | Hierarquia de Arquivos |
|---|---|---|
| Profundidade | Geralmente rasa (raramente excede 3 níveis). | Profunda (frequentemente 4, 5 ou mais níveis). |
| Duração (Vida) | Curta (geralmente minutos). | Longa (pode existir por anos). |
| Propriedade e Acesso | Controle restrito (geralmente pai-filho). | Acesso amplo (mecanismos para grupos/usuários). |
Todo arquivo dentro de uma hierarquia de diretórios pode ser especificado fornecendo o seu nome de caminho (path) a partir do topo da hierarquia, o diretório-raiz. Esses nomes de caminho absolutos consistem na lista de diretórios que precisam ser percorridos a partir da raiz para se chegar ao arquivo, com barras separando os componentes. Por exemplo, o caminho /Professores/Prof.Brown/Cursos/CS101 indica um caminho absoluto.
No Windows, o caractere barra invertida (\) é usado como separador em vez da barra (/) por razões históricas. Assim, o caminho acima seria escrito como \Professores\Prof.Brown\Cursos\CS101. No entanto, no contexto acadêmico e neste texto, utiliza-se a convenção UNIX.
A todo instante, cada processo possui um diretório de trabalho atual. Nomes de caminhos que não começam com uma barra são procurados neste diretório relativo. Os processos podem alterar seu diretório de trabalho emitindo uma chamada de sistema específica. Antes que um arquivo possa ser lido ou escrito, ele precisa ser aberto, momento em que as permissões são verificadas. Se o acesso for permitido, o sistema retorna um pequeno valor inteiro, chamado descritor de arquivo, para uso em operações subsequentes.
Outro conceito crucial no UNIX é a montagem do sistema de arquivos. A chamada de sistema mount permite que o sistema de arquivos de uma mídia removível (como CD-ROMs ou USBs) seja agregado à árvore principal do sistema de arquivos-raiz. Isso resolve o problema de endereçamento de dispositivos externos sem criar dependência de nomes de dispositivos (como letras de unidade), integrando tudo em uma única hierarquia lógica.
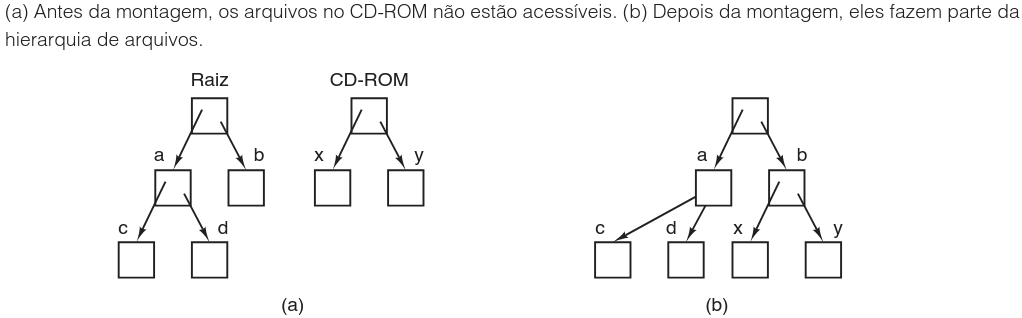
Além disso, o UNIX implementa o conceito de arquivo especial, que permite que dispositivos de E/S sejam tratados como arquivos. Eles são divididos em duas categorias principais:
- Arquivos especiais de bloco: Usados para modelar dispositivos que consistem em uma coleção de blocos endereçáveis aleatoriamente, como discos rígidos. Permitem acesso direto a blocos específicos.
- Arquivos especiais de caracteres: Usados para modelar dispositivos que operam com fluxo de caracteres, como impressoras e modems. Por convenção, esses arquivos são mantidos no diretório
/dev.
Por fim, um aspecto que relaciona processos e arquivos são os pipes. Um pipe é uma espécie de pseudoarquivo que conecta dois processos. Quando o processo A deseja enviar dados para o processo B, ele escreve no pipe como se fosse um arquivo de saída, e o processo B lê como se fosse um arquivo de entrada, conforme mostrado na figura abaixo:

A comunicação entre processos no UNIX assemelha-se muito à leitura e escrita de arquivos comuns. De fato, a única maneira de um processo descobrir se está escrevendo em um arquivo real ou em um pipe é através de uma chamada de sistema especial, o que demonstra a força da abstração de arquivos neste sistema operacional.
Entrada/Saída3.2.4
Todos os computadores dependem essencialmente de dispositivos físicos para obter entradas e produzir saídas. A utilidade de um sistema computacional reside justamente na capacidade de o usuário instruir a máquina e receber os resultados do processamento. Existem diversos tipos de dispositivos de entrada e saída (E/S), como teclados, monitores e impressoras, cabendo ao sistema operacional a responsabilidade crítica de gerenciá-los.
Em consequência dessa necessidade, todo sistema operacional implementa um subsistema de E/S. A estrutura desse software pode ser dividida em duas categorias principais, baseadas na especificidade do hardware controlado:
| Categoria de Software | Descrição e Função |
|---|---|
| Independente do Dispositivo | Software genérico que se aplica igualmente bem a muitos ou a todos os dispositivos de E/S, padronizando a interface. |
| Específico do Dispositivo | Software dedicado, conhecido como driver, projetado para lidar com as particularidades de um hardware específico. |
Proteção3.2.5
Os computadores modernos armazenam grandes volumes de informações que os usuários desejam manter confidenciais, incluindo e-mails, planos de negócios e declarações fiscais. Consequentemente, cabe ao sistema operacional gerenciar a segurança de forma que os recursos, como arquivos, sejam acessíveis apenas por usuários devidamente autorizados.
Para ilustrar o funcionamento da segurança, tomemos como exemplo o sistema UNIX. Neste ambiente, a proteção de arquivos é controlada por um código binário de 9 bits. Esse código é subdividido em três campos de 3 bits cada, atribuídos respectivamente ao proprietário, aos membros do grupo do proprietário (definidos pelo administrador do sistema) e aos demais usuários.
Cada campo é composto por três tipos de permissão, conforme detalhado na tabela a seguir:
| Símbolo | Permissão | Ação em Arquivos | Ação em Diretórios |
|---|---|---|---|
| r | Leitura (Read) | Ler o conteúdo do arquivo. | Listar o conteúdo do diretório. |
| w | Escrita (Write) | Alterar ou salvar o arquivo. | Criar/apagar arquivos no diretório. |
| x | Execução (Execute) | Executar o arquivo como programa. | Permissão de busca (entrar no diretório). |
A ausência de uma permissão é representada por um traço (-). Para compreender a aplicação prática desses bits, analise o exemplo abaixo:
rwxr-x--xEste código de permissão deve ser lido em blocos de três:
- Proprietário (
rwx): Tem permissão total para ler, escrever e executar. - Grupo (
r-x): Pode ler e executar, mas não pode escrever (alterar) o arquivo. - Outros (
--x): Podem apenas executar o arquivo, sem permissão para ler seu conteúdo ou alterá-lo.
Além da proteção de arquivos individuais, existem muitas outras questões críticas de segurança, como a proteção do sistema contra intrusos indesejados, sejam eles humanos ou softwares maliciosos como vírus.
O interpretador de comandos (shell)3.2.6
O sistema operacional é, fundamentalmente, o código responsável pela execução das chamadas de sistema. É importante distinguir que editores, compiladores, montadores, ligadores e interpretadores de comandos não fazem parte do sistema operacional em si, embora sejam ferramentas essenciais. O interpretador de comandos, conhecido como shell, serve como a principal interface entre o usuário e o sistema (na ausência de uma interface gráfica), fazendo uso intensivo das chamadas de sistema. Exemplos populares incluem sh, csh, ksh e bash.
O funcionamento do shell segue um ciclo lógico: quando um usuário se conecta, o shell é iniciado e apresenta um prompt (como o cifrão $), indicando que aguarda um comando. Ao receber um comando, como date, o shell cria um processo filho e executa o programa solicitado. O shell aguarda o término desse processo filho antes de exibir o prompt novamente para a próxima instrução.
Uma das funcionalidades mais poderosas do shell é a capacidade de manipular a entrada e a saída de dados, redirecionando fluxos entre arquivos e processos. A tabela abaixo resume os principais operadores de redirecionamento e controle de fluxo:
| Operador | Função | Exemplo | Descrição do Exemplo |
|---|---|---|---|
> |
Redirecionamento de Saída | date >file |
Salva a saída do comando date no arquivo file. |
< |
Redirecionamento de Entrada | sort <file1 >file2 |
O comando sort recebe dados de file1 e salva o resultado ordenado em file2. |
\| |
Pipe (Canalização) | cat f1 f2 \| sort |
A saída do cat (concatenação) vira a entrada imediata do sort. |
& |
Execução em Background | command & |
O shell não espera o comando terminar e libera o prompt imediatamente. |
Esses recursos permitem a construção de sequências complexas de processamento. Considere o exemplo abaixo, onde três arquivos são concatenados, ordenados alfabeticamente e enviados para a impressora, tudo em uma única linha de comando:
cat file1 file2 file3 | sort >/dev/lp &
Neste caso específico, o símbolo & no final instrui o shell a executar toda a tarefa em segundo plano, permitindo que o usuário continue trabalhando enquanto o processamento ocorre.
A maioria dos computadores modernos utiliza uma Interface Gráfica de Usuário (GUI). É fundamental compreender que a GUI, seja o Gnome/KDE no Linux ou o Windows Explorer no Windows, é apenas um programa sendo executado sobre o sistema operacional, funcionando de maneira análoga a um shell visual. No Linux, isso é evidente pela possibilidade de alternar entre diferentes GUIs; no Windows, embora raro, também é possível substituir a interface padrão alterando registros do sistema.
Chamadas de sistema3.3
A interação entre os programas de usuários e o sistema operacional ocorre fundamentalmente através de abstrações. Embora o sistema operacional tenha a função de gerenciar recursos, para o usuário, a interface manifesta-se em operações como criar, ler e deletar arquivos. Para compreender verdadeiramente o funcionamento de um sistema operacional, é imperativo examinar essa interface de perto, especificamente através das chamadas de sistema. Embora variem de sistema para sistema, os conceitos subjacentes tendem a ser similares. Adotaremos aqui uma abordagem prática baseada no padrão POSIX (International Standard 9945-1), que fundamenta sistemas como UNIX, Linux, BSD e MINIX 3.
Uma chamada de sistema não é uma simples chamada de função. Como um computador de uma única CPU executa apenas uma instrução por vez, um processo em modo de usuário que necessita de um serviço do sistema (como ler um arquivo) deve executar uma instrução de armadilha, conhecida como TRAP. Essa instrução transfere o controle para o sistema operacional, alterando o estado da máquina de modo usuário para modo núcleo (kernel), permitindo a execução de operações privilegiadas.
Para ilustrar esse mecanismo complexo, analisaremos a chamada de sistema read. Esta função possui três parâmetros essenciais: o descritor do arquivo, um ponteiro para o buffer (onde os dados serão armazenados) e o número de bytes a serem lidos. Em um programa C, a chamada seria estruturada da seguinte forma:
contador = read(fd, buffer, nbytes);
Se a chamada for bem-sucedida, a variável contador recebe o número de bytes lidos. Caso ocorra um erro (parâmetro inválido ou falha de disco), o retorno é -1 e o código do erro é armazenado na variável global errno.
A execução de uma chamada de sistema envolve uma sequência precisa de etapas. A figura abaixo detalha os 11 passos necessários para realizar a chamada read, desde a preparação na pilha até o retorno ao programa do usuário:
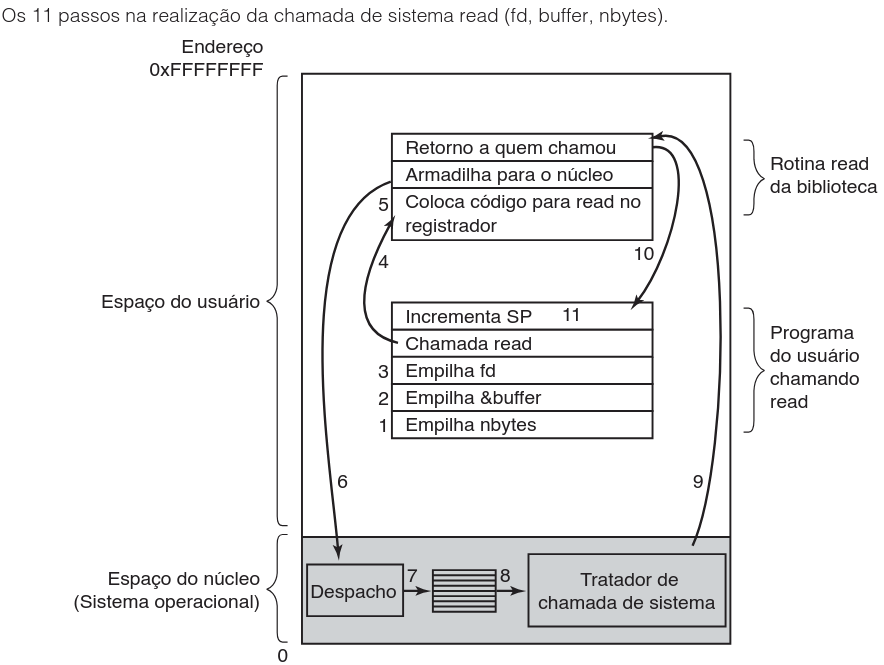
Acompanhe a descrição detalhada do fluxo apresentado na figura:
- Empilhamento de Parâmetros (Passos 1-3): O programa chamador empilha os parâmetros. Compiladores C empilham na ordem inversa (nbytes, &buffer, fd) para facilitar o acesso ao primeiro parâmetro. Note que o buffer é passado por referência (endereço).
- Chamada da Biblioteca (Passo 4): A rotina de biblioteca
readé invocada. Esta é uma chamada de função normal. - Preparação do Registrador (Passo 5): A biblioteca coloca o número identificador da chamada de sistema em um registrador específico onde o SO espera encontrá-lo.
- Instrução TRAP (Passo 6): Executa-se a instrução TRAP. Aqui ocorre a mudança crítica do modo usuário para o modo núcleo e o salto para um endereço fixo no kernel.
- Despacho (Passo 7): O código do núcleo examina o número da chamada (no registrador) e usa uma tabela de ponteiros para despachar o controle ao tratador correto.
- Execução (Passo 8): O tratador da chamada de sistema executa a operação solicitada.
- Retorno ao Usuário (Passos 9-10): Após a conclusão, o controle retorna à rotina de biblioteca (logo após a instrução TRAP) e, em seguida, ao programa do usuário.
- Limpeza da Pilha (Passo 11): O programa do usuário incrementa o ponteiro da pilha para remover os parâmetros que foram empilhados, finalizando o processo.
A instrução TRAP difere de uma chamada de rotina comum em dois aspectos fundamentais:
- Mudança de Modo: A TRAP altera o estado do processador de modo usuário para modo núcleo, algo que uma chamada comum (
CALL) não faz. - Endereçamento: A TRAP não salta para um endereço arbitrário, mas sim para locais fixos controlados pelo sistema (vetor de interrupção), garantindo segurança.
É importante ressaltar que o sistema operacional pode bloquear o chamador no Passo 9. Se o programa tentar ler do teclado e não houver entrada, ele ficará suspenso. O SO então alocará a CPU para outro processo até que a entrada esteja disponível.
Por fim, vale notar que o mapeamento entre rotinas da biblioteca POSIX e chamadas de sistema reais não é necessariamente de um para um. O padrão POSIX define a API, mas não a implementação. Algumas funções da biblioteca podem ser executadas inteiramente no espaço do usuário por desempenho, enquanto outras podem agrupar várias funcionalidades em uma única chamada de sistema, dependendo da arquitetura do SO.
Chamadas de sistema para gerenciamento de processos3.3.1
O gerenciamento de processos constitui um dos pilares fundamentais dos sistemas operacionais, sendo operado através de um conjunto específico de chamadas de sistema. A chamada fork é a única maneira de criar um novo processo em sistemas compatíveis com POSIX. Ela cria uma cópia exata do processo original, duplicando descritores de arquivos e registradores. Após a execução do fork, o processo original (pai) e a cópia (filho) seguem caminhos distintos. Embora as variáveis tenham valores idênticos no momento da criação, os dados são copiados, de modo que alterações subsequentes em um não afetam o outro, exceto pelo segmento de texto do programa, que é inalterável e compartilhado. O valor de retorno da chamada fork permite distinguir os processos: retorna zero para o processo filho e o PID (Identificador de Processo) do filho para o processo pai.
Para facilitar a compreensão das principais chamadas de sistema POSIX, organizamos a tabela abaixo, que agrupa as funções por categoria de gerenciamento:
| Categoria | Chamada de Sistema | Descrição e Funcionalidade |
|---|---|---|
| Processos | pid = fork() |
Cria um processo filho idêntico ao pai. |
pid = waitpid(pid, &statloc, options) |
Aguarda a conclusão de um processo filho. | |
s = execve(name, argv, environp) |
Substitui a imagem do núcleo de um processo. | |
exit(status) |
Conclui a execução e devolve o status. | |
| Arquivos | fd = open(file, how, ...) |
Abre arquivo para leitura, escrita ou ambos. |
s = close(fd) |
Fecha um arquivo aberto. | |
n = read(fd, buffer, nbytes) |
Lê dados de um arquivo para um buffer. | |
n = write(fd, buffer, nbytes) |
Escreve dados de um buffer em um arquivo. | |
| Diretórios | s = mkdir(name, mode) |
Cria um novo diretório. |
s = mount(special, name, flag) |
Monta um sistema de arquivos. | |
| Diversos | s = chdir(dirname) |
Altera o diretório de trabalho. |
s = kill(pid, signal) |
Envia um sinal para um processo. |
Na maioria dos casos, o processo filho executa um código diferente do pai. Um exemplo clássico é o funcionamento do shell. Após ler um comando, o shell cria um processo filho que executa a instrução enquanto o pai aguarda. Para realizar essa espera, utiliza-se a chamada waitpid, que suspende a execução até que o filho termine, permitindo recuperar o estado de saída (normal ou erro) através da variável statloc.
Simultaneamente, o processo filho utiliza a chamada execve para substituir sua imagem de memória pelo programa solicitado. Embora existam variações como execl ou execv na biblioteca padrão, todas invocam a chamada de sistema base exec. Abaixo, apresentamos um modelo simplificado da lógica de um interpretador de comandos:
O código a seguir ilustra o ciclo infinito de um shell: exibir prompt, ler comando, criar filho (fork), e decidir entre esperar (waitpid) ou executar (execve).
#define TRUE 1
while (TRUE) {
type_prompt(); /* mostra prompt na tela */
read_command(command, parameters); /* le entrada do terminal */
if (fork() != 0) {
/* Codigo do processo pai */
waitpid(-1, &status, 0); /* aguarda o processo filho acabar */
} else {
/* Codigo do processo filho */
execve(command, parameters, 0); /* executa o comando */
}
}
A função main da maioria dos programas C recebe três argumentos fundamentais para lidar com a linha de comando: argc (contagem de argumentos), argv (ponteiro para o array de argumentos) e envp (ponteiro para o ambiente). Por exemplo, ao executar cp fd1 fd2, o sistema passa esses nomes de arquivos através do vetor argv para que o programa possa localizá-los e processá-los.
Por fim, é crucial entender como esses processos ocupam a memória. Em sistemas UNIX, a memória é dividida em três segmentos principais: texto (código), dados (variáveis) e pilha. Conforme ilustrado na figura a seguir, o segmento de dados cresce para cima, enquanto a pilha cresce para baixo, deixando uma lacuna de endereçamento livre entre eles para expansão dinâmica.
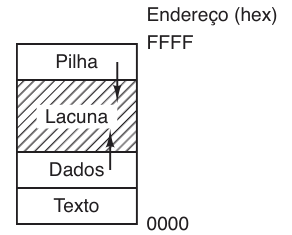
Embora a pilha cresça automaticamente, a expansão do segmento de dados é gerida explicitamente. A chamada de sistema brk define o novo endereço de término do segmento de dados, embora programadores geralmente utilizem a função de biblioteca malloc para alocação dinâmica, abstraindo o uso direto do brk.
Chamadas de sistema para gerenciamento de arquivos3.3.2
Muitas chamadas de sistema relacionam-se diretamente ao sistema de arquivos. Nesta seção, o foco recairá sobre as chamadas que operam sobre arquivos individuais, deixando para um momento posterior aquelas que envolvem diretórios ou o sistema de arquivos como um todo. O ciclo de vida básico de manipulação de um arquivo começa com a necessidade de abri-lo antes de qualquer leitura ou escrita. A chamada de sistema open é responsável por essa tarefa, exigindo o nome do arquivo (seja um caminho absoluto ou relativo ao diretório de trabalho) e um código de modo de acesso.
Os códigos de acesso determinam como o arquivo será manipulado, conforme descrito na tabela abaixo:
| Flag de Acesso | Significado | Descrição |
|---|---|---|
| O_RDONLY | Read Only | Abre o arquivo apenas para leitura. |
| O_WRONLY | Write Only | Abre o arquivo apenas para escrita. |
| O_RDWR | Read/Write | Abre o arquivo para leitura e escrita. |
| O_CREAT | Create | Cria um novo arquivo caso ele não exista. |
Uma vez aberto, o sistema retorna um descritor de arquivo, que será utilizado nas operações subsequentes. Após o término do uso, o arquivo deve ser fechado através da chamada close, o que libera o descritor para ser reutilizado em uma nova chamada open. As operações de leitura e escrita são realizadas pelas chamadas read e write, respectivamente, sendo que write possui os mesmos parâmetros de read.
Embora a leitura e a escrita sequenciais sejam comuns, certas aplicações necessitam de acesso aleatório a partes específicas de um arquivo. Para gerenciar isso, o sistema mantém um ponteiro associado a cada arquivo que indica a posição atual (byte) a ser lido ou escrito. A chamada de sistema lseek permite alterar explicitamente o valor desse ponteiro.
A função lseek aceita três parâmetros fundamentais para reposicionar o ponteiro do arquivo:
- Descritor de arquivo: O identificador do arquivo aberto.
- Posição (Offset): O deslocamento desejado.
- Referência: Define se a posição é relativa ao início, à posição atual ou ao fim do arquivo.
O valor retornado é a nova posição absoluta em bytes após a mudança.
Por fim, o sistema operacional UNIX registra metadados cruciais para cada arquivo, como tipo (regular, especial, diretório), tamanho e hora da última modificação. Para acessar essas informações, os programas utilizam a chamada de sistema stat.
// Exemplo de estrutura de chamada
int stat(const char *name, struct stat *buf);
int fstat(int fd, struct stat *buf);
A diferença principal entre as duas variações reside no primeiro parâmetro: stat recebe o nome do caminho do arquivo, enquanto fstat opera sobre um descritor de arquivo já aberto, mas ambas preenchem a estrutura apontada por buf com as mesmas informações detalhadas.
Chamadas de sistema para gerenciamento de diretórios3.3.3
Além das operações em arquivos individuais, o sistema operacional oferece chamadas que gerenciam diretórios e o sistema de arquivos como um todo. As operações mais básicas incluem mkdir e rmdir, utilizadas respectivamente para criar e remover diretórios vazios. Um conceito mais sofisticado é introduzido pela chamada link, cuja finalidade é permitir que um mesmo arquivo apareça sob dois ou mais nomes, frequentemente em diretórios distintos.
A criação de um link difere fundamentalmente da cópia de um arquivo. Ao compartilhar um arquivo via link, qualquer alteração realizada por um usuário é instantaneamente visível para os outros, pois existe apenas uma instância física do arquivo no disco. Em contrapartida, mudanças em cópias afetam apenas a versão específica editada. Para ilustrar o funcionamento do link, considere o cenário onde dois usuários, ast e jim, possuem diretórios próprios. Se ast executa a chamada de sistema abaixo, o arquivo memo de jim passa a aparecer também no diretório de ast com o nome note.
link("/usr/jim/memo", "/usr/ast/note");
A partir desse momento, /usr/jim/memo e /usr/ast/note referem-se exatamente ao mesmo arquivo. A figura a seguir demonstra o estado dos diretórios antes e depois dessa operação de ligação:
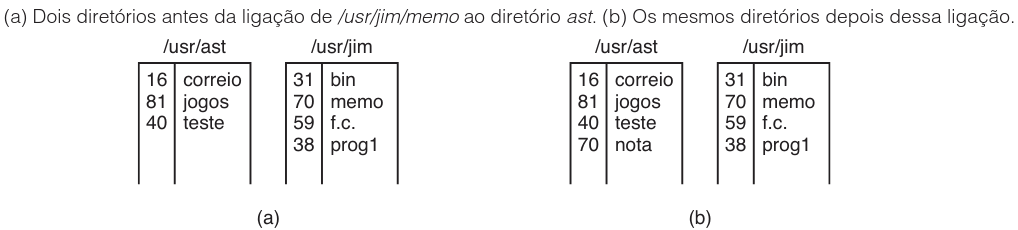
Para compreender a mecânica por trás disso, é necessário entender o conceito de i-número (ou i-nó). Todo arquivo no UNIX é identificado por um número único, que serve de índice em uma tabela de i-nós contendo metadados como proprietário e localização dos blocos no disco. Um diretório, conceitualmente, é apenas um arquivo que contém um conjunto de pares (i-número, nome em ASCII).
O comando link não duplica o conteúdo do arquivo; ele apenas cria uma nova entrada de diretório com um nome (possivelmente novo) apontando para o i-número de um arquivo já existente.
No exemplo da figura acima, observe que após a ligação, duas entradas (nos diretórios de jim e ast) apontam para o mesmo i-número (70). Se qualquer uma dessas entradas for removida posteriormente usando a chamada unlink, a outra permanece intacta. O arquivo só é efetivamente removido do disco quando o contador de referências no i-nó chega a zero, ou seja, quando não existem mais entradas de diretório apontando para ele.
Outra funcionalidade crítica para a integridade do sistema é a chamada mount, que permite a fusão de dois sistemas de arquivos distintos em uma única hierarquia. É comum ter o sistema raiz em uma partição e arquivos de usuário ou dispositivos externos (como pen drives USB) em outras. A chamada mount anexa o sistema de arquivos do dispositivo externo à árvore principal, eliminando a necessidade de o usuário saber em qual unidade física o arquivo reside.

Um comando típico para realizar essa operação, montando a unidade /dev/sdb0 no diretório /mnt, seria:
mount("/dev/sdb0", "/mnt", 0);
O primeiro parâmetro especifica o arquivo especial de bloco do dispositivo, o segundo define o ponto de montagem na árvore, e o terceiro controla flags de leitura/escrita. Após a montagem, os arquivos do dispositivo tornam-se acessíveis através do caminho do diretório, integrando mídias removíveis de forma transparente. Quando o acesso não for mais necessário, o sistema de arquivos pode ser desconectado utilizando a chamada umount.
Chamadas de sistema diversas3.3.4
Além das funções de gerenciamento de processos e arquivos, o sistema operacional oferece uma variedade de outras chamadas de sistema essenciais. Nesta seção, examinaremos quatro delas: chdir, chmod, kill e time. Elas desempenham papéis cruciais na navegação de diretórios, segurança, comunicação entre processos e contagem de tempo.
A tabela abaixo resume a funcionalidade de cada uma dessas chamadas:
| Chamada de Sistema | Função Principal | Exemplo de Uso Prático |
|---|---|---|
| chdir | Altera o diretório de trabalho atual. | Evita a digitação repetitiva de caminhos absolutos longos. |
| chmod | Altera o modo de proteção de um arquivo. | Define permissões de leitura, escrita e execução. |
| kill | Envia sinais a processos. | Permite comunicação ou encerramento forçado de processos. |
| time | Retorna o tempo atual em segundos. | Baseia-se no "Epoch" (1º de janeiro de 1970). |
A chamada chdir facilita a navegação no sistema de arquivos. Ao alterar o diretório de trabalho, o sistema permite que o usuário referencie arquivos de forma relativa, simplificando os comandos. Por exemplo, após executar chdir("/usr/ast/test"), qualquer tentativa de abrir o arquivo "xyz" será interpretada automaticamente como /usr/ast/test/xyz.
No que tange à segurança, o UNIX atribui a todo arquivo um modo de proteção, composto por bits de leitura, escrita e execução para o proprietário, o grupo e outros usuários. A chamada chmod permite alterar esses bits. O código abaixo exemplifica como configurar um arquivo para ser "somente leitura" para todos, exceto o proprietário (usando a notação octal 0644):
chdir("/usr/ast/test"); /* Muda o diretório */
chmod("file", 0644); /* Define permissões: rw-r--r-- */
Para a comunicação entre processos, utiliza-se a chamada kill. Apesar do nome sugestivo, sua função primária é enviar sinais. Se o processo destinatário estiver preparado para capturar o sinal, uma rotina de tratamento específica é executada. No entanto, se o processo não estiver preparado para lidar com o sinal recebido, a ação padrão é encerrar (matar) o processo, o que explica a origem do nome da chamada.
Por fim, o padrão POSIX define rotinas para lidar com o tempo. A chamada time retorna o tempo atual medido em segundos decorridos desde a "Era UNIX" ou Epoch (meia-noite de 1º de janeiro de 1970).
Em computadores que utilizam palavras de 32 bits, o valor máximo que a chamada time pode retornar (presumindo um inteiro sem sinal) é $2^{32} - 1$ segundos. Esse valor corresponde a aproximadamente 136 anos.
Isso significa que, no ano de 2106, sistemas UNIX de 32 bits baseados em inteiros sem sinal atingirão seu limite e poderão falhar, de maneira análoga ao famoso "Bug do Milênio" (Y2K). Embora pareça distante, a recomendação técnica para sistemas de longa vida é a migração para arquiteturas de 64 bits.
Estrutura de sistemas operacionais3.4
Após explorarmos a interface externa apresentada ao programador, o foco desloca-se agora para a arquitetura interna dos sistemas operacionais. A análise de como esses sistemas são construídos por dentro revela um amplo espectro de possibilidades de design e implementação.
Nas seções seguintes, examinaremos seis estruturas distintas que foram testadas na prática, oferecendo uma visão abrangente sobre a engenharia de software de sistemas:
- Sistemas Monolíticos: Onde o núcleo opera como um único programa em espaço de kernel.
- Sistemas de Camadas: Organização hierárquica onde cada nível confia apenas no nível inferior.
- Micronúcleos: Filosofia de manter o núcleo o menor possível, movendo serviços para o espaço do usuário.
- Sistemas Cliente-Servidor: Variação onde processos servidores respondem a requisições de clientes.
- Máquinas Virtuais: Abstração que cria múltiplas instâncias isoladas de hardware.
- Exonúcleos: Foco na alocação segura de recursos brutos, sem abstrações de alto nível.
Antes de detalhar essas arquiteturas, é pertinente estabelecer um paralelo entre os ambientes operacionais mais comuns. A figura e a tabela a seguir ilustram a correspondência aproximada entre as chamadas de sistema UNIX (discutidas anteriormente) e as chamadas da API Win32.
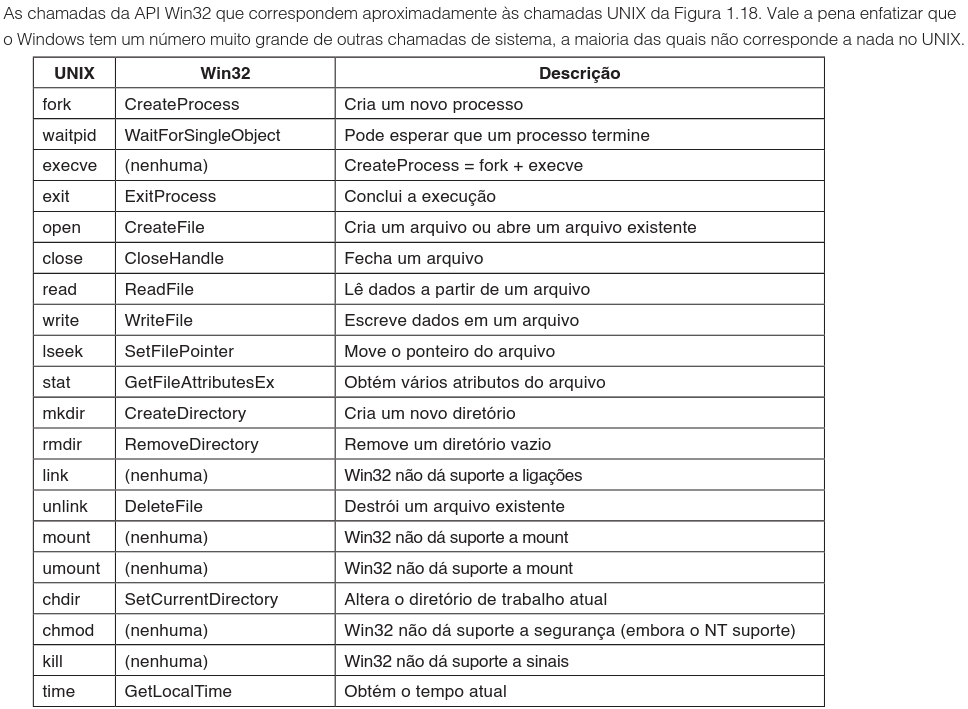
Embora o Windows possua um número vastamente superior de chamadas de sistema, muitas sem equivalente direto no UNIX, as funções essenciais de gerenciamento mapeiam-se da seguinte forma para fins de comparação:
| Funcionalidade | UNIX (POSIX) | Win32 API (Windows) |
|---|---|---|
| Criação de Processo | fork |
CreateProcess |
| Espera de Processo | waitpid |
WaitForSingleObject |
| Execução de Programa | execve |
(Combinado em CreateProcess) |
| Saída de Processo | exit |
ExitProcess |
| Abrir Arquivo | open |
CreateFile |
| Ler Arquivo | read |
ReadFile |
| Escrever Arquivo | write |
WriteFile |
| Fechar Arquivo | close |
CloseHandle |
| Criar Diretório | mkdir |
CreateDirectory |
| Remover Arquivo | unlink |
DeleteFile |
É importante enfatizar que a API Win32 é significativamente mais complexa que o padrão POSIX. Enquanto o UNIX foca em primitivas simples, o Windows tende a fornecer chamadas ricas em parâmetros. A tabela acima é uma simplificação didática para demonstrar a equivalência funcional.
Sistemas monolíticos3.4.1
De longe a organização mais comum no design de software de base, a abordagem monolítica caracteriza-se pela execução de todo o sistema operacional como um único programa em modo núcleo. O sistema é construído como uma coleção de rotinas ligadas a um único grande binário executável. Nesta arquitetura, qualquer procedimento tem a liberdade de chamar qualquer outro procedimento, caso este ofereça alguma computação útil necessária.
Embora essa liberdade irrestrita proporcione alta eficiência de execução, a interdependência de milhares de procedimentos pode resultar em um sistema complexo e de difícil compreensão. Além disso, a estabilidade é comprometida, pois uma falha crítica em qualquer rotina individual tem o potencial de derrubar todo o sistema operacional. Para construir o programa objeto, compilam-se todas as rotinas individuais que são posteriormente unificadas por um ligador (linker). Em termos de engenharia de software, praticamente não há ocultação de informações, pois todas as rotinas são visíveis entre si, ao contrário de estruturas modulares onde o acesso é restrito a pontos de entrada oficiais.
Mesmo dentro dessa estrutura maciça, existe uma organização lógica para o processamento de chamadas de sistema. Os serviços são solicitados colocando-se parâmetros em um local definido (como a pilha) e executando uma instrução de desvio de controle (trap). Essa instrução alterna a máquina do modo usuário para o modo núcleo e transfere o controle para o sistema operacional. O sistema então consulta uma tabela de despacho que contém ponteiros para as rotinas de serviço correspondentes.
Essa organização sugere uma estrutura básica dividida em três níveis funcionais, conforme ilustrado na figura a seguir:
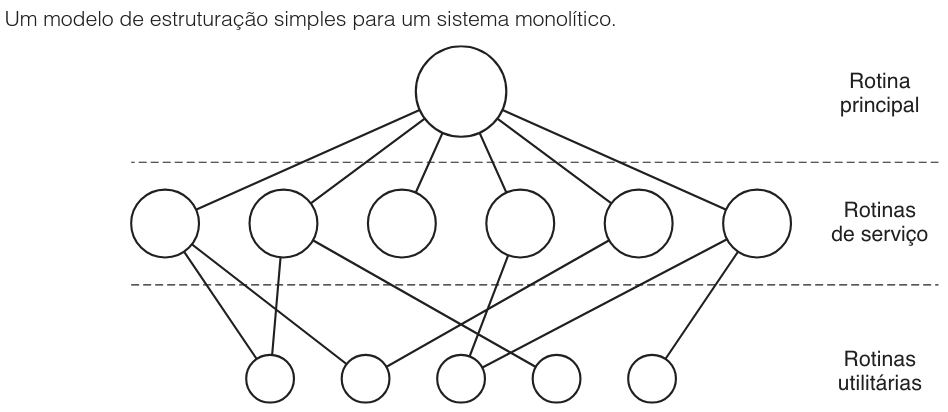
Cada nível desempenha um papel específico no atendimento às solicitações do usuário, detalhado na tabela abaixo:
| Nível da Estrutura | Função Principal |
|---|---|
| Programa Principal | Invoca a rotina de serviço requisitada após a interrupção (trap). |
| Rotinas de Serviço | Executam as chamadas de sistema específicas (o trabalho real do SO). |
| Rotinas Utilitárias | Auxiliam as rotinas de serviço em tarefas comuns, como buscar dados do usuário. |
Embora o núcleo seja monolítico, muitos sistemas modernos suportam extensões carregáveis sob demanda, como drivers de dispositivos e sistemas de arquivos.
- UNIX: Utiliza bibliotecas compartilhadas.
- Windows: Utiliza DLLs (Dynamic Link Libraries, ou bibliotecas de ligação dinâmica). O diretório
C:\Windows\system32tipicamente contém milhares desses arquivos, essenciais para a flexibilidade do sistema.
Sistemas de camadas3.4.2
Uma generalização da abordagem monolítica consiste em organizar o sistema operacional como uma hierarquia de camadas, onde cada nível é construído sobre a camada imediatamente inferior. O primeiro sistema construído sob essa filosofia foi o sistema THE, desenvolvido na Technische Hogeschool Eindhoven, na Holanda, por E. W. Dijkstra e seus estudantes em 1968. O THE era um sistema em lote simples projetado para o computador Electrologica X8, que possuía uma memória restrita de 32 K palavras de 27 bits.
A arquitetura do sistema THE foi dividida em seis camadas distintas, conforme ilustrado na figura a seguir:

Cada camada tinha uma responsabilidade específica e fornecia uma abstração para as camadas superiores, simplificando o desenvolvimento. A estrutura funcional é detalhada na tabela abaixo:
| Camada | Função Principal | Abstração Fornecida |
|---|---|---|
| 0 | Alocação do processador e multiprogramação. | Processos sequenciais (abstração de múltiplas CPUs). |
| 1 | Gerenciamento de memória e paginação (tambor magnético). | Memória virtual (independência do armazenamento físico). |
| 2 | Comunicação Operador-Processo. | Console de operação individual para cada processo. |
| 3 | Gerenciamento de E/S e buffering. | Dispositivos de E/S abstratos e simplificados. |
| 4 | Programas de Usuário. | Ambiente de execução isolado do hardware bruto. |
| 5 | Operador do Sistema. | Controle geral do sistema. |
Outra generalização importante do conceito de camadas foi implementada no sistema MULTICS. Em vez de camadas lineares, o MULTICS utilizava uma série de anéis concêntricos. Os anéis internos eram mais privilegiados que os externos. Quando um procedimento em um anel exterior necessitava chamar um procedimento em um anel interior, ele executava uma instrução de desvio (TRAP). Os parâmetros dessa chamada eram rigorosamente verificados antes que o acesso fosse concedido, garantindo a segurança.
A diferença fundamental entre as duas abordagens reside na implementação da proteção. Enquanto o esquema de camadas do THE era principalmente um suporte de projeto (compilado em um único programa executável), o mecanismo de anéis do MULTICS estava presente em tempo de execução e era imposto pelo hardware. O hardware permitia designar segmentos de memória protegidos contra leitura, escrita ou execução.
A vantagem do mecanismo de anéis é a extensibilidade para subsistemas de usuário. Imagine um professor que deseja criar um sistema automático de notas:
- O programa do professor (corretor) roda no anel n.
- Os programas dos estudantes (submetidos para teste) rodam no anel n + 1.
Dessa forma, os programas dos estudantes podem ser executados e analisados pelo corretor, mas o hardware impede que eles acessem ou alterem os dados (como as notas) que residem no anel mais privilegiado.
Micronúcleos3.4.3
A decisão sobre onde traçar a linha divisória entre o modo núcleo e o modo usuário é fundamental no design de sistemas operacionais. Tradicionalmente, a abordagem de camadas coloca a maior parte das funcionalidades dentro do núcleo. No entanto, existe um forte argumento em defesa do micronúcleo, que preconiza manter o mínimo possível de código rodando em modo privilegiado. A justificativa principal é a confiabilidade: erros no código do núcleo podem derrubar o sistema instantaneamente, enquanto processos de usuário, com menos privilégios, têm falhas contidas.
Estudos sobre engenharia de software indicam que a densidade de erros em sistemas industriais sérios varia entre dois e dez erros por mil linhas de código. Aplicando essa métrica a um sistema operacional monolítico moderno, que pode conter cinco milhões de linhas, é provável que existam entre 10.000 e 50.000 bugs no núcleo. Embora nem todos sejam fatais, essa vulnerabilidade explica por que fabricantes de hardware ainda incluem botões de reinicialização física em seus equipamentos, algo incomum em outros dispositivos eletrônicos de consumo.
A filosofia do micronúcleo visa atingir alta confiabilidade dividindo o sistema em módulos pequenos e bem definidos. Apenas o micronúcleo executa em modo núcleo; todo o restante, incluindo drivers de dispositivos e sistemas de arquivos, roda como processos de usuário com poderes limitados. A tabela abaixo ilustra o impacto dessa arquitetura na estabilidade do sistema:
| Característica | Sistema Monolítico | Sistema de Micronúcleo |
|---|---|---|
| Localização dos Drivers | Dentro do Núcleo (Kernel Mode) | Processos de Usuário (User Mode) |
| Acesso à Memória | Irrestrito | Restrito e Controlado |
| Falha em Driver (ex: Áudio) | O sistema inteiro trava (Crash/Tela Azul) | Apenas o som para, o sistema continua estável |
| Recuperação | Reinicialização total necessária | O componente pode ser reiniciado individualmente |
Embora sistemas de desktop comuns (exceto o OS X, baseado no Mach) raramente usem micronúcleos puros, eles são dominantes em aplicações críticas como aviônica, sistemas militares e industriais. Exemplos notáveis incluem Integrity, QNX, L4 e o MINIX 3. O MINIX 3, em particular, leva a modularidade ao extremo e serve como um excelente estudo de caso, sendo um sistema compatível com POSIX e de código aberto.
O núcleo do MINIX 3 é extremamente enxuto, contendo cerca de 12.000 linhas de C e 1.400 linhas de Assembly. Ele gerencia apenas o essencial: tratamento de interrupções, escalonamento básico e comunicação entre processos (troca de mensagens). A estrutura de processos resultante é visualizada na figura a seguir, onde os tratadores de chamadas de núcleo são rotulados como Sys:

Fora do núcleo, o sistema organiza-se em camadas de processos em modo usuário. Na base, encontram-se os drivers de dispositivos. Como não possuem acesso direto às portas físicas de E/S, eles devem solicitar ao núcleo que realize a escrita ou leitura, permitindo que o sistema verifique as permissões de acesso antes de executar a operação. Acima dos drivers, residem os servidores (como o servidor de arquivos e o gerenciador de processos), que executam a maior parte do trabalho do sistema operacional.
Uma característica distintiva do MINIX 3 é o Servidor de Reencarnação. Sua função é monitorar a saúde dos outros servidores e drivers. Se um driver de áudio ou de rede falhar, este servidor detecta o problema e substitui o componente defeituoso automaticamente, sem intervenção do usuário, conferindo ao sistema uma capacidade de "autocura".
A segurança é reforçada através de restrições rigorosas. Cada processo possui permissões granulares: drivers só tocam em portas autorizadas e a comunicação entre processos é controlada. Além disso, essa arquitetura facilita a separação entre política e mecanismo. O núcleo fornece o mecanismo (por exemplo, como trocar de processo), enquanto processos de usuário definem a política (quais prioridades atribuir), permitindo um núcleo menor e mais estável.
O modelo cliente-servidor3.4.4
Uma variação arquitetural importante, frequentemente derivada da filosofia do micronúcleo, é o modelo cliente-servidor. Esta abordagem distingue duas classes fundamentais de processos: os servidores, responsáveis por prestar serviços, e os clientes, que consomem esses serviços. Embora a camada inferior seja muitas vezes um micronúcleo, a essência do modelo reside na separação clara de responsabilidades e na comunicação via troca de mensagens.
Para solicitar um serviço, o processo cliente constrói uma mensagem detalhando sua requisição e a envia ao processo servidor apropriado. O servidor processa a solicitação e retorna uma resposta. Uma das grandes vantagens desse modelo é a capacidade de abstração e transparência de localização. Como a comunicação ocorre via mensagens, o cliente não precisa saber se o servidor está sendo executado localmente na mesma máquina ou remotamente através de uma rede.
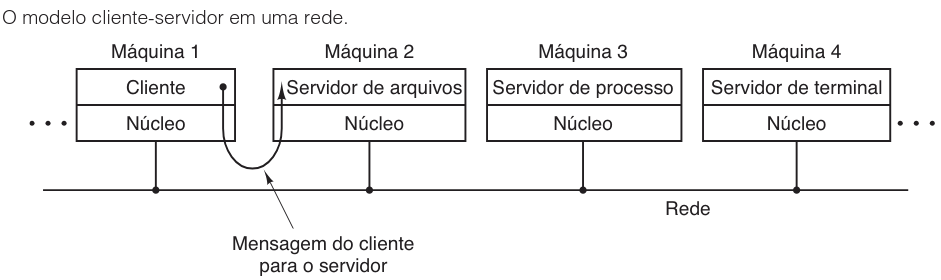
Essa flexibilidade permite que o modelo cliente-servidor seja aplicado tanto em sistemas monousuários quanto em grandes redes distribuídas, como a Web, onde PCs residenciais atuam como clientes solicitando páginas a grandes servidores remotos.
| Componente | Função Principal | Exemplo Prático |
|---|---|---|
| Cliente | Inicia a solicitação de serviço através de mensagens. | Navegador Web (solicita uma página). |
| Servidor | Processa a requisição, executa o trabalho e retorna a resposta. | Servidor Web (entrega o HTML/conteúdo). |
| Rede/Kernel | Transporta a mensagem (transparente para o cliente). | Internet ou Barramento de Mensagens Local. |
Máquinas virtuais3.4.5
Os lançamentos iniciais do OS/360 caracterizavam-se por serem estritamente sistemas em lote (batch). No entanto, a crescente necessidade dos usuários por operações interativas via terminal impulsionou diversos grupos, tanto dentro quanto fora da IBM, a desenvolverem sistemas de compartilhamento de tempo. A resposta oficial da IBM, o TSS/360, enfrentou problemas severos de desempenho e atrasos, resultando em seu abandono após consumir cerca de 50 milhões de dólares em desenvolvimento.
Paralelamente a esse insucesso, pesquisadores do Centro Científico da IBM em Cambridge, Massachusetts, produziram uma arquitetura alternativa radicalmente diferente que obteve êxito comercial e técnico. A trajetória desses sistemas está resumida na tabela abaixo:
| Sistema | Status e Impacto |
|---|---|
| OS/360 | Sistema original de lote. Carecia de interatividade. |
| TSS/360 | Tentativa falha de time-sharing. Lento e custoso. |
| CP/CMS | O sistema inovador de Cambridge que introduziu a virtualização eficiente. |
| z/VM | O descendente moderno, padrão da indústria atual. |
O legado desse desenvolvimento persiste no moderno z/VM, amplamente executado nos computadores de grande porte da família IBM zSeries. Esses equipamentos constituem a espinha dorsal de grandes centros de processamento de dados corporativos, sendo fundamentais para servidores de comércio eletrônico. Eles são capazes de processar milhares de transações por segundo e gerenciar bancos de dados cujos tamanhos atingem a escala de milhões de gigabytes.
A aceitação do sistema desenvolvido em Cambridge pela IBM marcou um ponto de virada, transformando a virtualização de uma ideia experimental em um produto comercial viável que sustenta a infraestrutura crítica mundial até hoje.
VM/3703.4.5.1
O sistema originalmente denominado CP/CMS, e mais tarde renomeado VM/370 (Seawright e MacKinnon, 1979), foi fundamentado em uma observação astuta sobre a natureza dos sistemas operacionais. Seus criadores notaram que um sistema de compartilhamento de tempo fornece simultaneamente duas funcionalidades distintas: multiprogramação e uma máquina estendida com uma interface mais conveniente que o hardware bruto. A essência inovadora do VM/370 reside na separação completa dessas duas funções.
O núcleo do sistema, conhecido como Monitor de Máquina Virtual, opera diretamente sobre o hardware e realiza a multiprogramação. Sua função não é fornecer uma abstração de alto nível, mas sim criar várias máquinas virtuais para a camada seguinte. Diferentemente de outros sistemas operacionais, essas máquinas virtuais não são máquinas estendidas com arquivos e recursos abstratos. Em vez disso, elas são cópias exatas do hardware exposto, incluindo modos núcleo/usuário, dispositivos de E/S, interrupções e todas as características da máquina física, conforme ilustrado na figura a seguir:
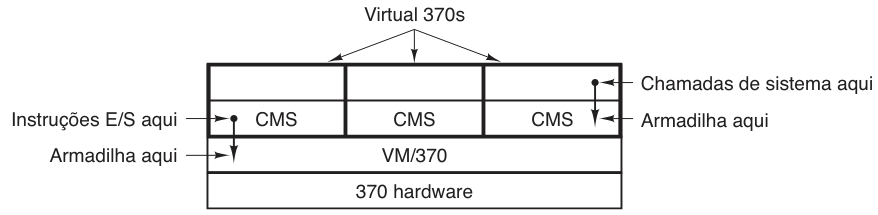
Como cada máquina virtual é idêntica ao hardware original, cada uma delas possui a capacidade de executar qualquer sistema operacional que rodaria diretamente no hardware físico. Isso permite que diferentes máquinas virtuais executem, simultaneamente, diferentes sistemas operacionais. No contexto do VM/370 original da IBM, era comum observar a seguinte configuração mista:
| Tipo de Sistema | Exemplo de OS | Uso Típico |
|---|---|---|
| Batch (Lote) | OS/360 | Processamento de transações pesadas ou tarefas em lote. |
| Interativo | CMS (Conversational Monitor System) | Sistema monousuário para programadores e tempo compartilhado. |
O funcionamento técnico dessa virtualização envolve um processo de interceptação e simulação. Quando um programa CMS executa uma chamada de sistema, esta é desviada para o sistema operacional residente em sua própria máquina virtual (o próprio CMS), e não diretamente para o VM/370. O CMS, agindo como se estivesse no hardware real, emite instruções normais de E/S para ler seu disco virtual.
As instruções de E/S emitidas pelo sistema hóspede (CMS) são interceptadas (capturadas por uma armadilha) pelo VM/370. O monitor então executa essas instruções como parte de sua simulação do hardware real. Ao separar a multiprogramação da provisão da máquina estendida, cada parte torna-se mais simples, flexível e fácil de manter.
Em sua encarnação moderna, o sistema evoluiu para o z/VM. Diferentemente do uso histórico com sistemas monousuários desmontados como o CMS, o z/VM é frequentemente utilizado para executar sistemas operacionais completos e modernos. Por exemplo, os mainframes zSeries são capazes de hospedar centenas ou milhares de máquinas virtuais Linux operando lado a lado com sistemas operacionais IBM tradicionais, consolidando servidores e serviços em uma única infraestrutura robusta.
Máquinas virtuais redescobertas3.4.5.2
Embora a IBM tenha disponibilizado produtos de máquina virtual há quatro décadas, e empresas como Oracle e Hewlett-Packard tenham implementado suporte em servidores de alto desempenho, a virtualização foi amplamente ignorada no universo dos PCs até recentemente. Contudo, uma convergência de novas necessidades, softwares e tecnologias transformou esse conceito em um tópico de alto interesse.
Motivações para o Renascimento da Virtualização
A adoção massiva dessa tecnologia é impulsionada por demandas específicas de diferentes setores, desde a consolidação de servidores corporativos até a flexibilidade para usuários finais. A tabela abaixo resume os principais cenários de uso:
| Cenário | Problema Anterior | Solução via Virtualização |
|---|---|---|
| Consolidação de Servidores | Execução de múltiplos serviços (Web, FTP, E-mail) em máquinas físicas separadas ou com risco de conflito em um único SO. | Executar todos os serviços na mesma máquina física, isolados em VMs, sem que a falha de um derrube os outros. |
| Hospedagem Web | Escolha binária entre hospedagem compartilhada (barata, sem controle) e dedicada (cara, flexível). | Oferta de máquinas virtuais (VPS). O cliente tem controle total (root) a uma fração do custo de um servidor dedicado. |
| Usuários Finais | Necessidade de reiniciar o computador (dual-boot) para usar sistemas diferentes (ex: Windows e Linux). | Execução simultânea de múltiplos sistemas operacionais para acessar aplicativos exclusivos de cada plataforma. |
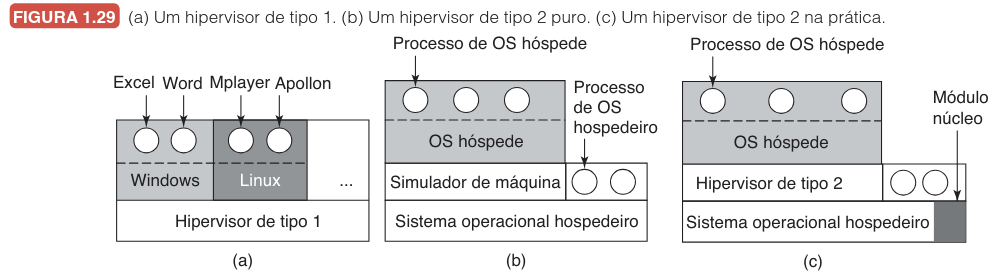
Para compreender a implementação técnica dessas soluções, é fundamental analisar a arquitetura dos Hipervisores. O termo "monitor de máquina virtual" foi modernamente renomeado para Hipervisor de Tipo 1, embora ambos os termos sejam usados. A figura a seguir ilustra a evolução e as variações dessas estruturas:
O Desafio da Implementação em x86
Apesar da atratividade do conceito, a implementação em PCs enfrentou obstáculos técnicos severos. Para que um software de virtualização funcione, a CPU deve ser virtualizável (Popek e Goldberg, 1974). Quando um SO hóspede tenta executar uma instrução privilegiada (como modificar a PSW ou realizar E/S), o hardware deve gerar uma armadilha (trap) para o hipervisor, permitindo a emulação segura.
Em CPUs antigas da família x86, notadamente o Pentium e seus clones, as tentativas de executar instruções privilegiadas em modo usuário eram simplesmente ignoradas pelo hardware, em vez de gerar uma armadilha. Essa falha arquitetural impediu a virtualização direta, exigindo o uso de interpretadores lentos (como o Bochs) ou técnicas complexas de tradução binária.
A situação mudou com pesquisas acadêmicas na década de 1990, como o Disco (Stanford) e o Xen (Cambridge), que pavimentaram o caminho para produtos comerciais como VMware Workstation, VirtualBox, KVM e Hyper-V.
Evolução e Classificação dos Hipervisores
A evolução técnica partiu da simples interpretação para a tradução binária, onde blocos de código são traduzidos e armazenados em cache para reutilização (conforme a Figura 1.29b). O passo seguinte, adotado por quase todos os hipervisores comerciais modernos de desktop, foi a adição de um módulo de núcleo para realizar tarefas pesadas (Figura 1.29c). Embora tecnicamente híbridos, esses sistemas são classificados como Hipervisores de Tipo 2.
A distinção prática entre os dois tipos principais é vital para a compreensão da arquitetura de sistemas:
| Característica | Hipervisor Tipo 1 (Bare Metal) | Hipervisor Tipo 2 (Hosted) |
|---|---|---|
| Execução | Roda diretamente sobre o hardware (sem SO subjacente). | Roda sobre um Sistema Operacional Hospedeiro (Windows, Linux). |
| Gerenciamento | Gerencia sua própria armazenagem e particionamento bruto. | Usa o sistema de arquivos do SO hospedeiro (disco virtual = arquivo). |
| Exemplos | Xen, VMware ESXi, Hyper-V (Server). | VMware Workstation, VirtualBox. |
| Inicialização | O Hipervisor é o primeiro software a carregar. | O SO Hospedeiro carrega primeiro, depois o Hipervisor é iniciado como aplicação. |
Quando um sistema operacional hóspede é inicializado em um Hipervisor Tipo 2, ele se comporta como se estivesse no hardware real, iniciando processos e interfaces gráficas. Contudo, existe uma abordagem alternativa chamada Paravirtualização. Nela, o sistema operacional hóspede é modificado para remover as instruções de controle problemáticas e colaborar com o hipervisor, diferindo da virtualização pura onde o SO hóspede não tem consciência de que está sendo virtualizado.
A máquina virtual Java3.4.5.3
Uma aplicação distinta e fundamental do conceito de virtualização encontra-se na execução de programas Java. Quando a Sun Microsystems desenvolveu a linguagem de programação Java, criou simultaneamente uma arquitetura de computador abstrata denominada JVM (Java Virtual Machine, ou Máquina Virtual Java). Diferentemente das abordagens tradicionais, o compilador Java não produz código de máquina nativo para um processador específico (como x86 ou SPARC). Em vez disso, ele gera código para a JVM, que é posteriormente executado por um programa interpretador.
A principal vantagem dessa arquitetura é a portabilidade. O código compilado para a JVM pode ser enviado pela internet e executado em qualquer computador que possua um interpretador JVM instalado, independentemente do hardware ou sistema operacional subjacente. Se o compilador produzisse binários específicos (por exemplo, apenas para processadores SPARC), esses programas não poderiam ser distribuídos e executados universalmente com a mesma facilidade. Embora fosse teoricamente possível distribuir um emulador de SPARC, a arquitetura da JVM foi projetada para ser muito mais simples de interpretar.
Para ilustrar a diferença de abordagem, a tabela abaixo compara a compilação nativa tradicional com o modelo da JVM:
| Característica | Compilação Nativa (ex: C/C++) | Compilação Java (JVM) |
|---|---|---|
| Produto do Compilador | Código de máquina específico (Binário x86, ARM, etc.). | Bytecode (Instruções para a JVM). |
| Execução | Direta pelo hardware (CPU). | Interpretada pela JVM (Software). |
| Portabilidade | Baixa (Requer recompilação para cada plataforma). | Alta ("Escreva uma vez, execute em qualquer lugar"). |
| Dependência | Sistema Operacional e Hardware. | Presença da JVM instalada. |
Além da portabilidade, o uso da JVM oferece benefícios significativos de segurança. Como o código é executado por um intermediário (o interpretador), é possível implementar verificações rigorosas no código recebido antes de sua execução.
Se o interpretador for implementado adequadamente, os programas JVM podem ser executados em um ambiente protegido (frequentemente chamado de sandbox). Isso garante que o código não possa roubar dados, corromper a memória ou causar danos ao sistema hospedeiro, uma característica vital para aplicações distribuídas via internet.
Exonúcleos3.4.6
Uma estratégia distinta da virtualização tradicional, que clona a máquina inteira, consiste em dividir a máquina real, fornecendo a cada usuário um subconjunto estrito dos recursos disponíveis. Nesta abordagem, em vez de simular um disco completo para cada máquina virtual, o sistema pode alocar, por exemplo, os blocos de disco de 0 a 1.023 para uma máquina e os blocos de 1.024 a 2.047 para a próxima.
Na camada inferior, operando em modo núcleo, encontra-se um programa denominado exonúcleo (Engler et al., 1995). Sua tarefa fundamental é alocar recursos às máquinas virtuais e verificar cada tentativa de uso para assegurar que nenhuma máquina tente acessar os recursos alheios. Cada máquina virtual, no nível do usuário, executa seu próprio sistema operacional, similar ao VM/370 ou ao modo virtual 8086 do Pentium, mas com a restrição de utilizar apenas os recursos explicitamente alocados.
A principal vantagem técnica do esquema do exonúcleo é a eliminação de uma camada de mapeamento, o que reduz significativamente a sobrecarga do sistema. A tabela a seguir compara as duas abordagens de gerenciamento de recursos:
| Característica | Máquinas Virtuais Tradicionais | Arquitetura de Exonúcleo |
|---|---|---|
| Estratégia | Clonagem (Simulação de Hardware). | Particionamento (Divisão de Recursos). |
| Visão do Disco | Cada VM "pensa" que tem um disco completo (Blocos 0 a Max). | O SO sabe quais blocos físicos possui (ex: 1024 a 2047). |
| Gerenciamento | O VMM mantém tabelas complexas para remapear endereços virtuais para físicos. | O Exonúcleo apenas registra qual recurso pertence a qual VM. |
| Sobrecarga | Alta (devido ao remapeamento constante). | Baixa (apenas verificação de proteção). |
Ao remover a necessidade de remapear endereços de disco e outros recursos, o exonúcleo mantém as máquinas virtuais isoladas umas das outras com um custo computacional mínimo. Ele separa a multiprogramação (no núcleo) do código do sistema operacional (no usuário) de forma mais eficiente que a virtualização clássica, limitando-se a manter as máquinas virtuais distantes umas das outras.
Questões3.5
1. O texto descreve a evolução e a diversidade dos sistemas operacionais. Associe corretamente o tipo de sistema operacional (Coluna A) à sua característica ou exemplo principal (Coluna B).
| Coluna A | Coluna B |
|---|---|
| (1) Mainframe / Grande Porte | ( ) O sistema operacional funciona frequentemente apenas como uma biblioteca ligada à aplicação; foca em prazos rígidos. |
| (2) Tempo Real Crítico (Hard) | ( ) Otimizado para processar milhares de transações por segundo e gerenciar volumes massivos de E/S; ex: OS/390. |
| (3) Computadores Pessoais | ( ) Sistemas onde a perda ocasional de um prazo é aceitável e não causa danos permanentes; ex: Áudio digital. |
| (4) Tempo Real Não Crítico (Soft) | ( ) Focado em fornecer uma interface robusta para um único usuário e suportar multitarefa para aplicações de escritório e web. |
2. Sobre o mecanismo de Chamadas de Sistema e a instrução TRAP, analise as afirmações abaixo e assinale a alternativa correta:
- a) A instrução TRAP é idêntica a uma chamada de função comum (
CALL), pois apenas desvia o fluxo para um endereço de memória onde reside a função do sistema. - b) A principal função da TRAP é alternar o estado do processador de modo usuário para modo núcleo (kernel), permitindo a execução de operações privilegiadas de forma segura.
- c) As chamadas de sistema no padrão POSIX são executadas inteiramente em modo usuário para garantir que uma falha no driver não derrube o sistema operacional.
- d) O comando
readacessa diretamente o hardware do disco sem passar pelo sistema operacional, utilizando a TRAP apenas para notificar o término da leitura.
3. Considere um sistema UNIX de 32 bits que utiliza um inteiro sem sinal para contar o tempo (chamada de sistema time). O texto menciona o "Problema do Ano 2106".
- a) Explique o que é o "Epoch" e qual a data base utilizada.
- b) Sabendo que o valor máximo de um inteiro sem sinal de 32 bits é $2^{32} - 1$, calcule aproximadamente quantos anos esse contador pode registrar a partir do Epoch.
- c) Por que a migração para arquiteturas de 64 bits é recomendada para solucionar este problema definitivamente?
4. O gerenciamento de processos utiliza chamadas específicas como fork e execve. Analise o trecho de código abaixo, que simula um shell simplificado, e responda:
if (fork() != 0) {
waitpid(-1, &status, 0);
} else {
execve(command, parameters, 0);
}
- a) Qual valor a chamada
fork()retorna para o processo pai e qual valor ela retorna para o processo filho? - b) Qual é a função da chamada
waitpidneste contexto e o que aconteceria com o shell (pai) se ela não fosse utilizada? - c) O que a chamada
execvefaz com a imagem de memória do processo filho?
5. A segurança em sistemas UNIX é gerida por bits de permissão. Considere um arquivo com as permissões exibidas como rwxr-x--x.
- a) Converta essa representação simbólica para a notação octal utilizada pela chamada
chmod(lembrando que r=4, w=2, x=1). - b) Descreva detalhadamente o que o Grupo e os Outros usuários podem e não podem fazer com este arquivo.
6. Sobre as Arquiteturas de Sistemas Operacionais, marque (V) para Verdadeiro ou (F) para Falso:
- ( ) Sistemas Monolíticos: Todo o sistema operacional roda como um único programa em modo núcleo; uma falha em um driver de áudio pode travar todo o computador.
- ( ) Micronúcleos: Visam alta confiabilidade movendo a maior parte do código (como drivers e sistemas de arquivos) para o espaço do usuário; ex: MINIX 3.
- ( ) Sistemas de Camadas: No modelo do sistema THE, a camada de mais alto nível era responsável pelo gerenciamento de memória e paginação.
- ( ) Máquinas Virtuais (Tipo 2): O hipervisor roda diretamente sobre o hardware ("bare metal"), sem a necessidade de um sistema operacional hospedeiro como Windows ou Linux.
- ( ) Exonúcleos: Em vez de clonar a máquina, essa arquitetura particiona os recursos (ex: blocos de disco específicos) e permite que cada máquina virtual gerencie seus próprios recursos alocados sem remapeamento complexo.
7. O sistema de arquivos UNIX permite a criação de links. Analise o cenário onde o usuário ast executa o comando link("/usr/jim/memo", "/usr/ast/note").
- a) O conteúdo do arquivo
memoé duplicado no disco para criar o arquivonote? Justifique usando o conceito de i-número. - b) Se o usuário jim remover o arquivo original
memousandounlink, o que acontece com o arquivonotede ast e com o conteúdo no disco? Explique o conceito de contador de referências.
8. Ordene cronologicamente as etapas que ocorrem durante a execução da chamada de sistema read, conforme descrito na arquitetura monolítica/POSIX:
- (A) A biblioteca coloca o número da chamada de sistema em um registrador.
- (B) O tratador da chamada de sistema executa a operação solicitada (trabalho real).
- (C) O programa do usuário empilha os parâmetros (nbytes, &buffer, fd).
- (D) A instrução TRAP é executada, mudando para modo núcleo.
- (E) O código do núcleo usa uma tabela de despacho para encontrar o tratador correto.
- (F) A biblioteca retorna ao programa do usuário, que limpa a pilha.
9. Diferencie Hipervisores de Tipo 1 e Hipervisores de Tipo 2 com base em:
- a) Localização da execução (sobre o que eles rodam?).
- b) Exemplos de softwares comerciais citados no texto para cada tipo.
10. Explique a filosofia do Modelo Cliente-Servidor em sistemas operacionais locais (não em rede) e como ela se relaciona com a arquitetura de Micronúcleos. Cite o benefício de "transparência de localização" mencionado no texto.
Próximos passos3.6
Na próxima aula, Processos e Threads, aprofundaremos nossa visão sobre a unidade fundamental de execução. Deixaremos de ver o processo apenas como uma abstração estática para entender sua dinâmica interna: estados de execução, escalonamento e a distinção crucial entre processos pesados e threads leves. Investigaremos como o sistema operacional orquestra a alternância rápida da CPU para criar a ilusão de paralelismo e como evitar condições de corrida em ambientes concorrentes.