Introdução5.1
Gerenciar a execução concorrente é um dos maiores desafios no projeto de sistemas operacionais modernos. Nas aulas anteriores, estudamos processos e threads como fluxos independentes de execução, operando em seus próprios espaços de endereçamento ou compartilhando recursos de forma simples. No entanto, para que um sistema computacional realize tarefas complexas e integradas, esses fluxos precisam de mecanismos robustos para colaborar e trocar informações.
Um navegador web que se comunica com um plugin de vídeo, ou um servidor que divide uma carga massiva de requisições entre vários núcleos de processamento, são exemplos de sistemas que dependem da Comunicação entre Processos (IPC). Sem uma sincronização precisa, a execução de múltiplos processos resultaria em dados corrompidos, sistemas travados e erros imprevisíveis que mudariam a cada execução. Nesta aula, exploraremos as camadas de hardware e software que garantem que essa coreografia de dados seja segura e eficiente.
Implementação de Threads (Revisão)5.1.1
A posição onde o sistema operacional decide gerenciar as threads (se no espaço do usuário ou diretamente no núcleo) determina de maneira fundamental a latência e a capacidade de resposta das aplicações. Quando optamos por threads no espaço do usuário, o núcleo do sistema permanece alheio à existência de múltiplos fluxos de execução dentro do processo. Uma biblioteca de tempo de execução (runtime library) gerencia uma tabela interna de threads, realizando o chaveamento de forma extremamente rápida, sem a necessidade de transições de privilégio pesadas (Traps). Contudo, essa eficiência vem com um custo alto: se uma única thread realizar uma chamada de sistema bloqueante, como uma leitura de disco, o núcleo suspende o processo inteiro, paralisando todas as outras threads que poderiam continuar trabalhando.
Em contrapartida, as threads no espaço do núcleo são reconhecidas e gerenciadas diretamente pelo escalonador do sistema operacional. Isso permite que, caso uma thread bloqueie por falta de dados ou uma falta de página (page fault), o núcleo possa escalonar outra thread do mesmo processo para ocupar a CPU. Embora esse modelo seja muito mais robusto e aproveite melhor o paralelismo real em máquinas multiprocessadores, cada operação de criação ou sincronização exige uma chamada de sistema completa, o que consome mais ciclos de processamento do que o modelo de usuário.
Existem ainda abordagens sofisticadas que tentam unir o melhor dos dois mundos, como as Ativações pelo Escalonador e o mecanismo de Upcalls. Nesse cenário, o núcleo fornece ao processo processadores virtuais e toma a iniciativa de notificar a biblioteca de threads do usuário sobre eventos relevantes. Se uma thread bloqueia no núcleo, o sistema faz uma chamada "de baixo para cima" (o upcall), permitindo que a aplicação decida localmente como redistribuir seu trabalho. Essa técnica, embora complexa, resolve o problema do bloqueio total no espaço do usuário sem perder a agilidade do escalonador local.
Se um servidor web usa threads no espaço do usuário e uma delas bloqueia esperando uma resposta do banco de dados, o que acontece com as outras threads? Por que isso seria catastrófico em produção? O que o modelo de threads no núcleo faria diferente neste cenário?
Comunicação entre Processos (IPC)5.1.2
A Comunicação entre Processos (IPC) não se resume apenas à simples transferência de bytes. Um sistema de IPC bem projetado deve resolver simultaneamente três problemas centrais: a transferência de dados entre espaços de endereçamento (que podem ser isolados fisicamente), a sincronização das atividades entre os processos e a manutenção da ordem correta de execução. Sem esses pilares, seria impossível para o Processo B saber se os dados produzidos pelo Processo A já estão prontos para consumo, ou se a leitura de um buffer compartilhado resultará em informações consistentes.
Os mecanismos físicos para realizar essa comunicação variam de acordo com a velocidade e o nível de isolamento desejado. A Memória Compartilhada é a forma mais rápida de IPC, pois permite que dois processos mapeiem a mesma região de RAM física em seus próprios endereços lógicos, eliminando a necessidade do núcleo copiar dados entre buffers. Outra abordagem clássica é o uso de Pipes (Canalizações), que funcionam como fluxos unidirecionais de dados. Os pipes são a base da filosofia UNIX, conectando ferramentas simples.
Antes de ver o código: como você imagina que dois processos independentes (com memórias separadas!) poderiam se comunicar? Quais seriam os problemas de sincronização que surgiriam naturalmente?
O exemplo abaixo mostra como um pai e um filho podem se comunicar de forma síncrona: o filho esperará automaticamente no read() até que o pai envie os dados.
Exemplo 1: Comunicação via Pipe em C5.1.2.1
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
int fd[2]; // fd[0]: leitura, fd[1]: escrita
pid_t pid;
if (pipe(fd) == -1) return 1;
pid = fork();
if (pid > 0) { // Processo PAI
close(fd[0]);
char msg[] = "Olá do processo Pai!";
write(fd[1], msg, strlen(msg) + 1);
close(fd[1]);
} else { // Processo FILHO
close(fd[1]);
char buffer[100];
read(fd[0], buffer, sizeof(buffer));
printf("Filho recebeu via pipe: %s\n", buffer);
close(fd[0]);
}
return 0;
}
No código do pipe, o filho chama read() que pode bloquear. O que aconteceria se o pai nunca escrevesse nada no pipe? O que o close(fd[0]) no processo pai e o close(fd[1]) no processo filho significam, e por que são necessários? O que aconteceria se fossemos omiti-los?
Condições de Corrida (Race Conditions)5.1.3
Uma condição de corrida surge no momento em que dois ou mais processos competem pelo acesso a um recurso compartilhado, e o resultado final depende da ordem exata em que o escalonador alterna a CPU. O grande perigo é que elas são falhas intermitentes: um programa pode funcionar perfeitamente durante centenas de testes e falhar subitamente em produção.
Para ilustrar este conceito, Tanenbaum utiliza a analogia do Spooler de Impressão. Imagine um diretório para arquivos de impressão com uma variável in apontando para o próximo slot livre. Se o Processo A ler in (descobrindo o slot 7) e for interrompido antes de gravar seu arquivo, o Processo B pode ser escalonado, ler o mesmo valor (7), gravar seu arquivo e atualizar in para 8. Quando o Processo A retomar, ele acreditará que o slot 7 ainda é dele, sobrescreverá o arquivo de B e também moverá o ponteiro para 8. O arquivo de B será perdido para sempre.
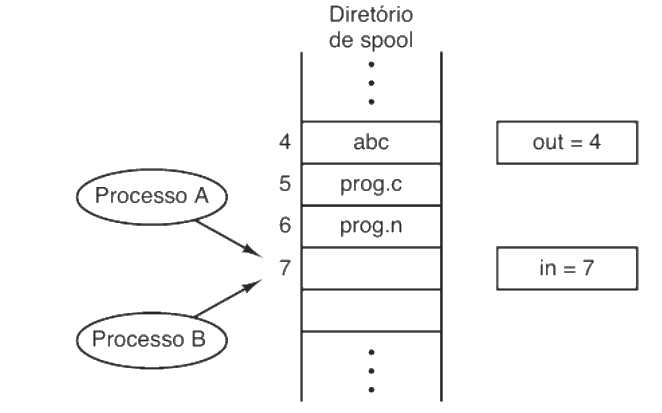
A falha ocorre porque operações como contador++ não são atômicas. Elas envolvem carregar o valor na CPU, incrementar e salvar. Se a CPU for chaveada no meio desse ciclo, a atualização será perdida. Observe o código abaixo, onde duas threads tentam chegar a 2 milhões, mas falham sistematicamente.
Exemplo 2: O Bug da Condição de Corrida5.1.3.1
#include <stdio.h>
#include <pthread.h>
long contador = 0;
void* incrementar(void* arg) {
for (int i = 0; i < 1000000; i++) {
contador++; // Operação não-atômica
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_create(&t1, NULL, incrementar, NULL);
pthread_create(&t2, NULL, incrementar, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("Resultado após corrida: %ld (Esperado: 2000000)\n", contador);
return 0;
}
Execute mentalmente (ou compile) o Exemplo 2. O resultado será sempre o mesmo? Por que contador++, que parece uma única instrução, não é atômica? Em que ponto exato o escalonador poderia interromper a thread e causar a inconsistência? Desenhe a linha do tempo.
Regiões Críticas e Exclusão Mútua5.1.4
Para curar o problema das condições de corrida, isolamos o código que acessa recursos compartilhados em Regiões Críticas (CR). O objetivo é implementar a Exclusão Mútua: garantir que se um processo está dentro de sua CR, todos os outros sejam impedidos de entrar.
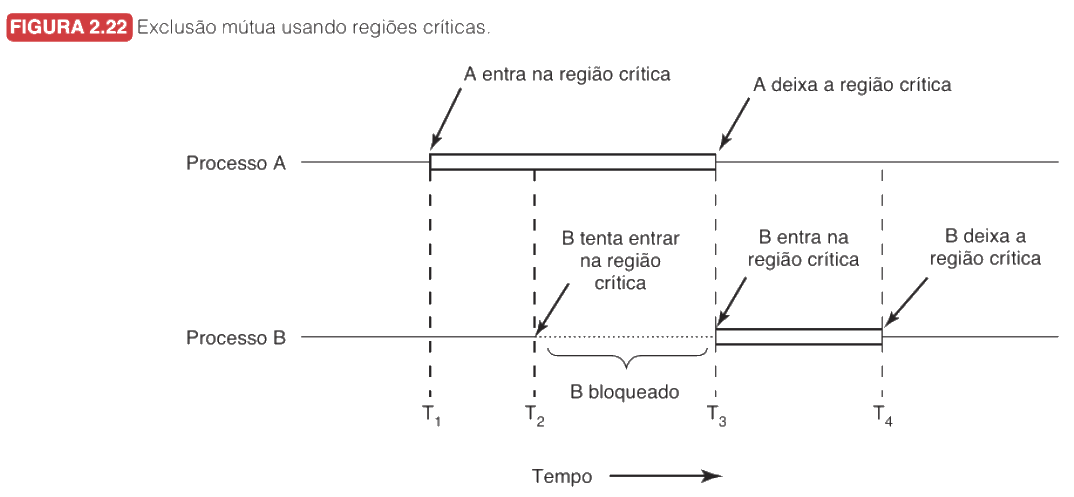
Qualquer solução de sincronização ideal deve obedecer a quatro condições: primeiro, a Exclusão Mútua Rígida (nunca dois processos na CR ao mesmo tempo). Segundo, a Independência de Hardware, funcionando sem supor o número de CPUs ou sua velocidade. Terceiro, o Não-Bloqueio Externo, onde um processo fora da CR não impede outros de entrarem nela. Por fim, a Espera Limitada, garantindo que nenhum processo espere eternamente (ausência de starvation).
A solução mais simples que alguém poderia imaginar é: "processo A seta lock = 1 e quando termina faz lock = 0". Essa solução atende às 4 condições listadas? Qual delas ela viola? (Dica: pense em duas threads lendo lock == 0 quase ao mesmo tempo.)
Exclusão Mútua com Espera Ocupada (Busy Waiting)5.1.5
As abordagens iniciais utilizavam a Espera Ocupada, onde o processo fica em um laço de repetição testando o valor de uma variável. Isso desperdiça CPU e pode causar a Inversão de Prioridade, onde uma thread importante fica presa esperando outra lenta liberar o processador.
Alguns métodos históricos incluem Desabilitar Interrupções (perigoso para o usuário) e a Alternância Estrita (que viola a condição 3 de progresso). No entanto, a Solução de Peterson (1981) provou ser possível via software puro para dois processos, combinando o conceito de "vez" com o "desejo de entrada". Em sistemas multiprocessadores modernos, o hardware provê suporte nativo via instruções como TSL (Test and Set Lock), que bloqueia o barramento de memória para garantir atomicidade.
Exemplo 3: Solução de Peterson Completa5.1.5.1
#include <stdio.h>
#include <pthread.h>
int vez;
int interesse[2] = {0, 0};
long contador = 0;
void enter_region(int process) {
int outro = 1 - process;
interesse[process] = 1;
vez = outro;
while (interesse[outro] && vez == outro);
}
void leave_region(int process) {
interesse[process] = 0;
}
void* worker(void* arg) {
int id = *(int*)arg;
for (int i = 0; i < 1000000; i++) {
enter_region(id);
contador++;
leave_region(id);
}
return NULL;
}
int main() {
pthread_t t1, t2;
int id0 = 0, id1 = 1;
pthread_create(&t1, NULL, worker, &id0);
pthread_create(&t2, NULL, worker, &id1);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("Resultado com Peterson: %ld\n", contador);
return 0;
}
O coração da solução de Peterson está no while (vez == process && interesse[outro] == 1). Trace o que acontece quando ambos os processos executam enter_region ao mesmo tempo: quais variáveis cada um escreve? Por que a última atribuição de vez é sempre a que "perde" a disputá e cede a vez ao outro? Isso garante qual das 4 condições?
Em nível didático, a solução de Peterson mostra que a exclusão mútua pode ser obtida apenas com software para dois processos. No entanto, essa ideia clássica não funciona de forma confiável em compiladores e arquiteturas modernas. O motivo é que o algoritmo assume que leituras e escritas em memória compartilhada serão observadas exatamente na ordem em que aparecem no código. Hoje essa suposição não vale mais de forma geral.
Compiladores modernos podem reorganizar instruções, manter valores em registradores e eliminar leituras repetidas quando entendem que isso preserva a semântica do programa segundo o modelo de memória da linguagem. Além disso, o próprio processador pode executar operações fora de ordem e tornar uma escrita visível para um núcleo em momento diferente do observado por outro. Assim, um processo pode testar interesse[outro] ou vez e enxergar um valor antigo, mesmo depois de o outro processo já ter feito a atualização correspondente.
Na prática, às vezes vemos uma melhora significativa no comportamento por conta de otimizações do compilador, do cache, da ordem de escalonamento e de características específicas da máquina. Mesmo assim, isso não é garantia de correção. O programa pode aparentar funcionar em muitos testes e ainda falhar em outra compilação, em outro processador ou em outra execução. Portanto, sem operações atômicas e barreiras de memória apropriadas, não podemos garantir exclusão mútua de forma correta e portável nos sistemas atuais.
Sono e Acordar (Sleep and Wakeup)5.1.6
Embora a Solução de Peterson e a instrução TSL garantam a exclusão mútua, elas sofrem de um defeito grave: o desperdício de CPU. Enquanto um processo espera para entrar em sua região crítica, ele consome ciclos de processamento repetindo um laço while. Além disso, a espera ocupada pode causar o fenômeno da Inversão de Prioridade: se um processo de alta prioridade fica pronto enquanto um de baixa prioridade está na região crítica, o processo de alta prioridade pode entrar em um loop infinito de espera, nunca cedendo a CPU para que o processo de baixa prioridade possa terminar e liberar o recurso.
Para resolver isso, utilizamos as primitivas sleep() (que bloqueia o processo, retirando-o da fila de prontos) e wakeup() (que o traz de volta). O exemplo clássico para ilustrar essas primitivas é o Problema do Produtor-Consumidor (também conhecido como o problema do buffer limitado). Aqui, o produtor tenta colocar itens em um buffer de tamanho fixo e o consumidor tenta retirá-los. Se o buffer estiver cheio, o produtor deve dormir; se estiver vazio, o consumidor deve dormir.
O Que Vai Errado: A Janela de Vulnerabilidade5.1.6.1
O problema reside na falta de atomicidade entre o teste de uma condição e a chamada de bloqueio. Imagine um cenário onde o buffer está vazio (count == 0):
- O consumidor executa
if (count == 0), confirma que é verdade, mas antes de conseguir dormir, é interrompido pelo escalonador. - O produtor entra, produz um item, incrementa
countpara 1 e, percebendo que o buffer agora tem conteúdo, tenta acordar o consumidor (wakeup). - Como o consumidor tecnicamente ainda não dormiu (ele foi interrompido logo antes), o sinal de
wakeupé perdido. - O consumidor retoma a execução exatamente onde parou e finalmente dorme.
- Eventualmente, o produtor encherá o buffer e também dormirá. Os dois ficarão dormindo para sempre: um Deadlock.
O que o sistema operacional precisaria "lembrar" para que esse sinal de wakeup não fosse ignorado? Essa falha seria fácil de detectar em testes comuns ou ela depende de uma coincidência temporal muito específica?
Semáforos e Mutexes5.1.7
Semáforos de Dijkstra5.1.7.1
Dijkstra introduziu os semáforos em 1965 como uma solução definitiva para o problema dos sinais perdidos. Um semáforo é uma variável inteira especial que armazena o número de "sinais de acordar" acumulados para uso futuro. Diferente do wakeup simples, que é ignorado se o processo não estiver dormindo, o sinal em um semáforo (operação UP) incrementa o contador. Se um processo tentar dormir (operação DOWN) logo em seguida, ele encontrará o contador positivo e continuará sem bloquear. O sinal foi "salvo".
As operações fundamentais devem ser atômicas (indivisíveis):
- DOWN (ou P): Verifica se o valor é > 0. Se for, decrementa e continua. Se for 0, o processo dorme sem completar o decremento até ser acordado.
- UP (ou V): Incrementa o valor. Se houver processos dormindo esperando, um deles acorda e completa seu
DOWN.
Diferente do wakeup simples, o UP em um semáforo incrementa o contador. Se um processo tentar um DOWN logo em seguida, ele encontrará o contador positivo e não precisará dormir. O sinal foi "salvo".
Por que é absolutamente crucial que as operações DOWN e UP sejam atômicas? O que aconteceria se dois processos tentassem decrementar um semáforo que está em 1 exatamente ao mesmo tempo e a CPU trocasse de contexto no meio da verificação?
Mutexes (Mutual Exclusion)5.1.7.2
O Mutex é um semáforo simplificado com apenas dois estados: trancado ou destrancado. É ideal para proteger estruturas de dados. Diferente do semáforo, o Mutex tem um "Dono". Abaixo, vemos como o Mutex resolve de forma limpa a condição de corrida que vimos anteriormente.
Exemplo 4: Mutex para Exclusão Mútua5.1.7.3
#include <stdio.h>
#include <pthread.h>
long contador = 0;
pthread_mutex_t trava;
void* incrementar(void* arg) {
for (int i = 0; i < 1000000; i++) {
pthread_mutex_lock(&trava);
contador++; // Região Crítica Protegida
pthread_mutex_unlock(&trava);
}
return NULL;
}
int main() {
pthread_t t1, t2;
pthread_mutex_init(&trava, NULL);
pthread_create(&t1, NULL, incrementar, NULL);
pthread_create(&t2, NULL, incrementar, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_mutex_destroy(&trava);
printf("Resultado com Mutex: %ld\n", contador);
return 0;
}
Compare o Exemplo 2 (com bug) e o Exemplo 4 (com mutex). A única diferença são as chamadas lock/unlock. Por que isso resolve o problema? Se você remover apenas o pthread_mutex_unlock (esqueceu de liberar), o que aconteceria? Já viu esse bug em algum software real?
Sincronização Real: O Problema do Produtor-Consumidor5.1.7.4
Abaixo, vemos a implementação real em C utilizando Semáforos para controle de fluxo (vagas e itens) e Mutex para proteção da região crítica (o acesso ao buffer). Esta arquitetura resolve a janela de vulnerabilidade pois as operações nos semáforos garantem que nenhum sinal de sincronização seja perdido.
Exemplo 5: Sincronização Produtor-Consumidor5.1.7.5
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#define BUFFER_SIZE 5
int buffer[BUFFER_SIZE];
int count = 0;
sem_t empty, full;
pthread_mutex_t mutex;
void* producer(void* arg) {
for (int i = 0; i < 10; i++) {
sem_wait(&empty); // Espera vaga (DOWN)
pthread_mutex_lock(&mutex);
buffer[count++] = i;
printf("Produtor: Inseriu item %d na posicao %d\n", i, count-1);
pthread_mutex_unlock(&mutex);
sem_post(&full); // Avisa que tem novo item (UP)
sleep(1);
}
return NULL;
}
void* consumer(void* arg) {
for (int i = 0; i < 10; i++) {
sem_wait(&full); // Espera item (DOWN)
pthread_mutex_lock(&mutex);
int item = buffer[--count];
printf("Consumidor: Removeu item %d da posicao %d\n", item, count);
pthread_mutex_unlock(&mutex);
sem_post(&empty); // Libera vaga (UP)
sleep(2);
}
return NULL;
}
int main() {
pthread_t p, c;
sem_init(&empty, 0, BUFFER_SIZE); // Inicializa com N vagas
sem_init(&full, 0, 0); // Inicializa com 0 itens
pthread_mutex_init(&mutex, NULL);
pthread_create(&p, NULL, producer, NULL);
pthread_create(&c, NULL, consumer, NULL);
pthread_join(p, NULL);
pthread_join(c, NULL);
return 0;
}
Se já existe um mutex protegendo o buffer, por que ainda precisamos dos semáforos empty e full? E, no sentido contrário, se os semáforos já controlam vagas e itens disponíveis, por que eles não substituem sozinhos o mutex na proteção da região crítica?
Problemas Clássicos de IPC5.1.8
Cinco filósofos sentam-se à mesa com cinco garfos. Cada filósofo precisa de dois garfos para comer. Se todos pegarem o garfo da esquerda ao mesmo tempo, teremos um Deadlock. A solução exige quebrar a circularidade da espera. Uma técnica é a Hierarquia de Recursos, onde um filósofo sempre tenta pegar o garfo de menor índice primeiro.

Antes de ver o código: imagine 5 filósofos pegando o garfo da esquerda simultaneamente. Desenhe o estado. Por que todos ficam travados? O que precisaria mudar para que pelo menos um filósofo consiga comer? Por que a solução de hierarquia de recursos funciona?
Exemplo 6: Solução Hierárquica para os Filósofos5.1.8.1
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#define N 5
#define LEFT (i + N - 1) % N
#define RIGHT (i + 1) % N
typedef enum { THINKING, HUNGRY, EATING } state_t;
state_t state[N];
sem_t mutex;
sem_t s[N];
void test(int i) {
if (state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] != EATING) {
state[i] = EATING;
printf("Filosofo %d pegou os garfos e esta COMENDO\n", i);
sem_post(&s[i]);
}
}
void take_forks(int i) {
sem_wait(&mutex);
state[i] = HUNGRY;
printf("Filosofo %d esta faminto (HUNGRY)\n", i);
test(i);
sem_wait(&mutex);
sem_wait(&s[i]);
}
void put_forks(int i) {
sem_wait(&mutex);
state[i] = THINKING;
printf("Filosofo %d devolveu os garfos e voltou a PENSAR\n", i);
test(LEFT);
test(RIGHT);
sem_post(&mutex);
}
pthread_mutex_t garfos[N];
void* filosofo(void* num) {
int i = *(int*)num;
while(1) {
printf("Filosofo %d esta PENSANDO...\n", i);
sleep(1);
// Tenta pegar garfos (Solucao hierarquica para evitar Deadlock)
if (i % 2 == 0) {
pthread_mutex_lock(&garfos[LEFT]);
pthread_mutex_lock(&garfos[RIGHT]);
} else {
pthread_mutex_lock(&garfos[RIGHT]);
pthread_mutex_lock(&garfos[LEFT]);
}
printf("Filosofo %d esta COMENDO\n", i);
sleep(1);
pthread_mutex_unlock(&garfos[LEFT]);
pthread_mutex_unlock(&garfos[RIGHT]);
}
}
int main() {
pthread_t thread_id[N];
int ids[N];
for (int i = 0; i < N; i++) {
pthread_mutex_init(&garfos[i], NULL);
ids[i] = i;
}
for (int i = 0; i < N; i++)
pthread_create(&thread_id[i], NULL, filosofo, &ids[i]);
for (int i = 0; i < N; i++)
pthread_join(thread_id[i], NULL);
return 0;
}
Monitores e Abstrações de Alto Nível5.1.9
Gerenciar semáforos manualmente é propenso a erros: um UP ou DOWN esquecido pode travar o sistema inteiro. Para evitar isso, surgiram os Monitores, uma abstraction de alto nível onde o compilador gerencia a exclusão mútua.
Um monitor é uma coleção de procedimentos, variáveis e estruturas de dados. A regra de ouro é: apenas um processo pode estar ativo dentro do monitor por vez. Se um processo chama um procedimento do monitor e já houver outro lá dentro, o novo processo será bloqueado automaticamente.
Variáveis de Condição: wait() e signal()5.1.9.1
Para permitir que processos bloqueiem dentro do monitor quando uma condição não é atendida (ex: buffer vazio), usamos Variáveis de Condição. Elas possuem duas operações:
- WAIT: O processo que a chama é bloqueado e libera temporariamente sua exclusão mútua do monitor, permitindo que outro processo entre.
- SIGNAL (ou notify): Acorda um processo que estava esperando naquela variável.
A principal diferença é que o SIGNAL em um monitor não tem memória. Se você der um signal e ninguém estiver esperando, o sinal desaparece. Em semáforos, o sinal (UP) sempre incrementa o contador. Por isso, em monitores, o wait deve estar sempre dentro de um loop while que retesta a condição ao acordar.
Questões5.2
1. A implementação de threads pode ser projetada para ocorrer no espaço do usuário ou diretamente no núcleo do sistema operacional. Com base nas diferenças arquiteturais entre essas abordagens, assinale a alternativa correta:
- A) As threads gerenciadas no espaço do núcleo são extremamente rápidas de chavear, pois não exigem transições de privilégio pesadas (Traps).
- B) O uso de "Ativações pelo Escalonador" agrava o problema de bloqueio total no espaço do usuário, pois o núcleo perde completamente a capacidade de comunicação com a biblioteca de threads.
- C) No modelo de espaço do usuário, se uma única thread realizar uma chamada de sistema bloqueante (como leitura de disco), o processo inteiro é suspenso pelo núcleo, paralisando todas as outras threads.
- D) O núcleo do sistema operacional reconhece nativamente os múltiplos fluxos de execução quando as threads operam exclusivamente no espaço do usuário.
2. Para evitar o problema das Condições de Corrida (Race Conditions), isolamos o código que acessa recursos compartilhados em Regiões Críticas (CR). Qualquer solução ideal de sincronização deve obedecer a quatro condições fundamentais. Relacione a Coluna A (Condição) com a Coluna B (Descrição correspondente):
| Coluna A | Coluna B |
|---|---|
| (1) Exclusão Mútua Rígida | ( ) Garante que nenhum processo precise esperar eternamente para obter o recurso (ausência de starvation). |
| (2) Independência de Hardware | ( ) Estabelece que nunca dois processos podem estar em sua Região Crítica simultaneamente. |
| (3) Não-Bloqueio Externo | ( ) A solução deve operar perfeitamente sem criar suposições sobre o número de CPUs disponíveis ou suas velocidades. |
| (4) Espera Limitada | ( ) Determina que um processo que esteja operando fora de sua Região Crítica não pode impedir que outros processos entrem nas suas. |
3. A Comunicação entre Processos (IPC) através de Pipes estabelece fluxos unidirecionais de dados. Analisando o código em C apresentado no Exemplo 1 para comunicação entre processos pai e filho, responda detalhadamente:
- a) Sabendo que a chamada
read()pode ser bloqueante, descreva o que ocorreria com o fluxo de execução do processo filho caso o processo pai jamais escrevesse dados no pipe. - b) Explique a importância e o impacto lógico de se utilizar
close(fd[0])no código do processo pai eclose(fd[1])no processo filho logo após a criação do pipe viafork().
4. O problema do Produtor-Consumidor ilustra falhas de sincronização conhecidas como Janela de Vulnerabilidade ao utilizar primitivas como sleep() e wakeup(). Assinale a alternativa que descreve a causa principal dessa vulnerabilidade:
- A) O Produtor envia um sinal de
wakeupexcessivamente rápido, esgotando o buffer de memória antes que o Consumidor possa processá-lo. - B) A falta de atomicidade entre o teste da variável
counte a execução da funçãosleep()permite que o escalonador interrompa o Consumidor, resultando na perda irreversível do sinal dewakeupemitido pelo Produtor. - C) A primitiva
sleep()consome altos ciclos de CPU durante a "Espera Ocupada", causando o fenômeno de Inversão de Prioridade. - D) O escalonador força o Produtor a dormir sempre que o buffer está vazio, impedindo a inserção de novos itens.
5. Sobre os Semáforos introduzidos por Dijkstra e os Monitores como abstrações de alto nível para controle de concorrência, analise as afirmativas abaixo e julgue-as como Verdadeiras (V) ou Falsas (F):
- ( ) A principal vantagem de um Semáforo é que suas operações UP e DOWN não necessitam ser atômicas, facilitando a implementação em hardware simples.
- ( ) O Mutex diferencia-se de um semáforo genérico por ser uma versão simplificada com apenas dois estados (trancado/destrancado) e possuir a noção de um "Dono".
- ( ) Em um Monitor, apenas um processo pode estar ativo dentro de sua estrutura por vez; processos adicionais que tentem entrar são bloqueados automaticamente pelo compilador.
- ( ) O comando
SIGNALem um Monitor possui uma "memória" idêntica à operaçãoUPdo Semáforo: se um sinal é emitido e não há ninguém esperando, ele incrementa um contador oculto para uso futuro.
6. Problemas clássicos de IPC exigem arquiteturas cuidadosas para prevenir falhas sistêmicas como Deadlocks e Starvation. Com base nas abordagens para os problemas dos Filósofos Comensais e dos Leitores-Escritores, responda:
- a) Qual estado exato conduz os cinco filósofos a um impasse (Deadlock) na analogia clássica?
- b) Como a implementação algorítmica da "Hierarquia de Recursos" rompe a circularidade de espera no problema dos Filósofos?
- c) No problema dos Leitores-Escritores, caso o sistema permita continuamente a entrada de novos leitores enquanto houver pelo menos um lendo a base de dados, qual consequência direta o Escritor enfrentará e qual o nome desse fenômeno?
Próximos passos5.3
Na próxima aula, entraremos na inteligência estratégica do sistema: o 6 - escalonamento. Descobriremos como o S.O. decide quem ganha o privilégio de usar a CPU e quais algoritmos garantem justiça e fluidez.