Sistemas Operacionais
Sistemas de Arquivos e Entrada/Saída
Professor: Gabriel Soares Baptista
Introdução
Hoje veremos como o SO transforma blocos crus e dispositivos lentos em uma interface simples.
Interface vista pelo programa:
- arquivos e diretórios
open,close,read,write,seek- operações de entrada e saída
Problema central: como armazenar informações de forma persistente, encontrável, compartilhável e eficiente, mesmo quando o hardware só entende blocos, controladores, interrupções e erros?
Da Memória Virtual aos Arquivos
Na aula anterior: memória virtual cria a ilusão de espaço grande, contínuo e privado.
Agora o problema muda:
- memória do processo desaparece quando o processo termina
- muitos dados precisam sobreviver por dias, meses ou anos
- dados precisam ser encontrados por nome
- dados precisam ser compartilhados e protegidos
Base: Tanenbaum, capítulo 4, seções 4.1 a 4.4, e capítulo 5, seções 5.1 a 5.3.
Pergunta Inicial
Quando você salva relatorio.txt, o que o sistema precisa lembrar?
- nome do arquivo
- onde estão os bytes
- quem pode acessar
- tamanho e datas
- quais blocos pertencem ao arquivo
- quais blocos ainda estão livres
O nome sozinho não basta. O sistema de arquivos precisa manter dados e metadados consistentes.
Arquivo: Abstração Persistente
Um arquivo é uma unidade lógica de informação criada por processos e gerenciada pelo SO.
Ele evita que o programa lide diretamente com:
- cilindros, setores e blocos físicos
- controladores de dispositivo
- temporização de hardware
- interrupções e erros
Para o programador: nome, conteúdo e operações.
Para o SO: metadados, blocos, permissões e relação com diretórios.
Por que Arquivos Existem?
| Necessidade | Por que importa |
|---|---|
| Armazenar muita informação | O espaço de endereçamento do processo não é o lugar certo para todos os dados |
| Sobreviver ao processo | O arquivo continua existindo depois que o processo termina |
| Permitir compartilhamento | Vários processos podem acessar a mesma informação por uma interface comum |
Arquivos resolvem o que a memória principal não resolve sozinha: persistência, escala e compartilhamento.
Nomes, Extensões e Tipos
Ao criar um arquivo, o processo dá um nome a ele.
Regras variam entre sistemas:
- UNIX/Linux distinguem maiúsculas e minúsculas
- MS-DOS historicamente não distinguia
- extensões como
.c,.txt,.jpg,.pdfindicam convenções
Em UNIX, extensão costuma ser convenção.
Em ambientes gráficos, extensão costuma ajudar a escolher o programa que abrirá o arquivo.
Extensão Não Garante Conteúdo
Um nome como foto.jpg sugere uma imagem JPEG.
Mas o sistema de arquivos pode não verificar isso.
O conteúdo real depende de:
- bytes armazenados
- formato interpretado pelo programa
- validação feita pela aplicação
Conclusão: extensão é pista, não prova.
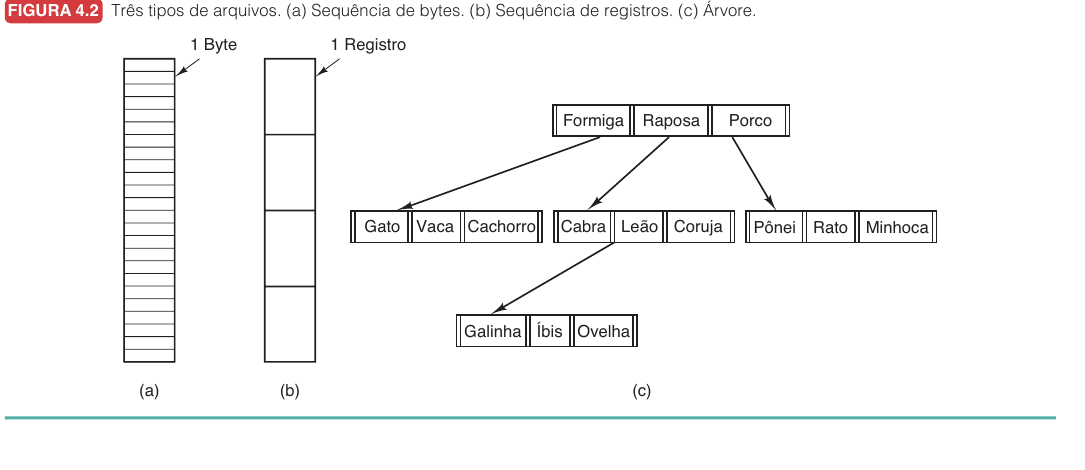
Estrutura Interna dos Arquivos
Tanenbaum apresenta três formas clássicas de enxergar arquivos.
| Estrutura | Ideia | Onde aparece |
|---|---|---|
| Sequência de bytes | SO não interpreta o conteúdo | UNIX, Linux, Windows modernos |
| Sequência de registros | Arquivo lido e escrito em registros | Sistemas antigos de grande porte |
| Árvore de registros | Registros buscados por chave | Processamento comercial |
Bytes, Registros e Árvores
Sequência de bytes:
- arquivo é uma sequência linear: byte 0, byte 1, byte 2...
- SO não sabe se é texto, imagem, vídeo ou executável
- interpretação fica nos programas de usuário
Sequência de registros:
- SO reconhece uma unidade maior que byte: o registro
- programa lê “o próximo registro”, não apenas “os próximos 200 bytes”
- fronteiras entre registros fazem parte da organização
Árvore de registros:
- cada registro possui uma chave
- busca pode navegar pela árvore em vez de percorrer tudo em ordem
Por que Bytes São Flexíveis?
Sequência de bytes é a opção mais flexível.
Vantagem:
- SO não precisa conhecer todos os formatos possíveis
- novos formatos não exigem alterar o kernel
- programas diferentes podem interpretar os mesmos bytes de formas diferentes
Desvantagem:
- SO ajuda menos
- se um programa interpreta bytes errados como imagem ou executável, o erro precisa ser tratado em outro nível
Acesso Sequencial e Aleatório
| Tipo | Como funciona | Exemplo |
|---|---|---|
| Sequencial | Lê ou escreve na ordem atual | Processar um log linha por linha |
| Aleatório | Move a posição atual e acessa dali | Buscar registro de cliente em uma base |
Primeiros sistemas: acesso sequencial combinava com fitas magnéticas.
Com discos: acesso aleatório se tornou viável.
Em UNIX e Windows, seek altera a posição atual do arquivo.
Atributos e Operações
Arquivos têm conteúdo e metadados.
| Atributo | O que representa |
|---|---|
| Proteção | Quem pode ler, escrever ou executar |
| Proprietário | Usuário responsável |
| Tamanho | Quantidade atual de bytes |
| Tempos | Criação, último acesso e última modificação |
| Flags | Somente leitura, oculto, temporário, sistema |
Operações comuns: create, delete, open, close, read, write, append, seek, get attributes, set attributes, rename.
O que open Faz?
Abrir um arquivo não significa ler todos os dados imediatamente.
open prepara o sistema para acessos futuros:
- localiza o arquivo
- carrega metadados relevantes
- cria uma entrada interna no kernel
- devolve ao processo um descritor de arquivo
Depois disso, read e write usam esse descritor.
Exemplo: Copiar Arquivo
abrir entrada.txt para leitura
criar saida.txt para escrita
enquanto houver bytes na entrada:
ler um bloco da entrada
escrever esse bloco na saída
fechar os dois arquivos
O programa não precisa saber onde estão os blocos físicos de entrada.txt.
O SO converte pedidos de bytes em:
- leituras de blocos
- uso de cache
- chamadas ao driver
- operações de E/S
Diretórios Transformam Nomes em Localização
Um sistema com milhares de arquivos não pode ser uma única lista plana.
Diretórios:
- organizam nomes
- agrupam arquivos relacionados
- associam nomes à informação necessária para localizar o arquivo
A informação associada pode ser:
- primeiro bloco do arquivo
- conjunto de atributos
- número de um i-node
Diretórios Hierárquicos
Sistemas modernos usam diretórios em árvore.
Isso permite organização por usuário, aplicação ou projeto.
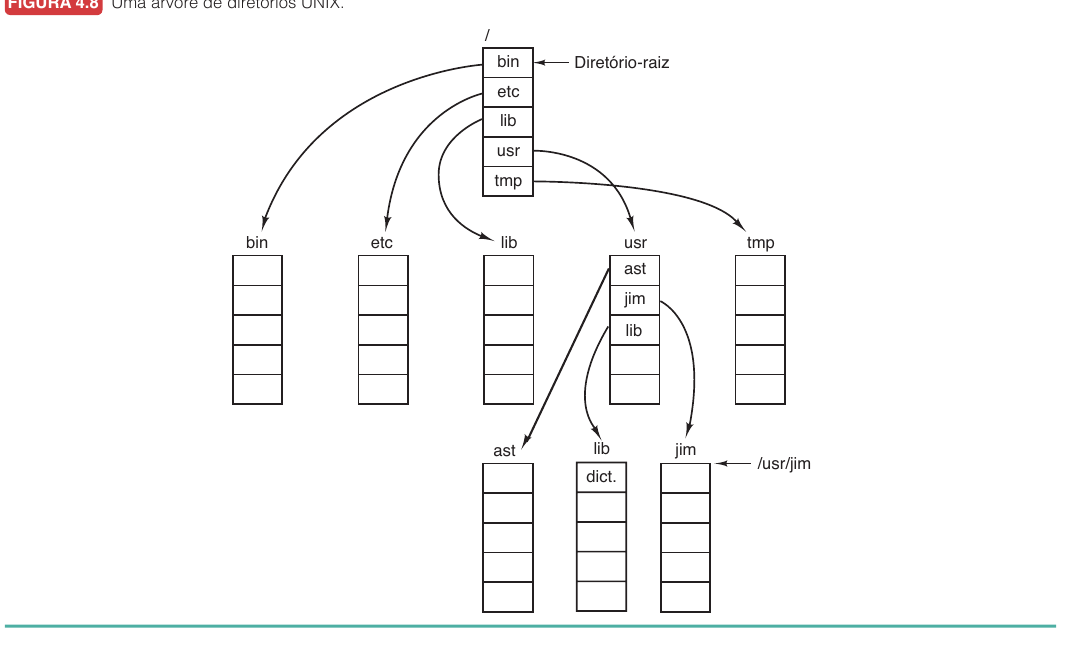
Caminhos Absolutos e Relativos
| Tipo | Ideia | Exemplo |
|---|---|---|
| Absoluto | Começa na raiz | /usr/ast/caixapostal |
| Relativo | Começa no diretório atual | caixapostal |
Diretório de trabalho: referência usada por caminhos relativos.
Se o diretório atual é /usr/ast, então caixapostal e /usr/ast/caixapostal apontam para o mesmo arquivo.
Nomes especiais:
.é o diretório atual..é o diretório pai
Operações com Diretórios
| Operação | Função |
|---|---|
create | Cria diretório vazio |
delete | Remove diretório, geralmente se estiver vazio |
opendir | Abre diretório para leitura |
readdir | Retorna próxima entrada |
closedir | Fecha diretório |
rename | Renomeia uma entrada |
link | Faz um arquivo aparecer por outro nome |
unlink | Remove uma entrada de diretório |
Em UNIX, remover arquivo é remover uma ligação nome → arquivo. Por isso: unlink.
Links Rígidos e Simbólicos
| Tipo | Como funciona | Consequência |
|---|---|---|
| Link rígido | Duas entradas apontam para a mesma estrutura interna | Arquivo só desaparece quando o último nome é removido |
| Link simbólico | Pequeno arquivo guarda caminho para outro arquivo | Pode atravessar sistemas de arquivos, mas pode quebrar |
Links rígidos tornam o sistema mais parecido com um grafo acíclico do que com uma árvore pura.
Link simbólico quebrado não é arquivo corrompido: o link existe, mas a resolução do caminho falha.
Implementação no Disco
Agora olhamos o sistema de arquivos pelo lado de quem implementa.
Disco simplificado: sequência de blocos.
Perguntas que o sistema precisa responder:
- Quais blocos pertencem a cada arquivo?
- Quais blocos estão livres?
- Onde ficam os metadados?
- Como encontrar o diretório-raiz?
- Como recuperar o sistema após uma queda?
Esquema Geral de uma Partição
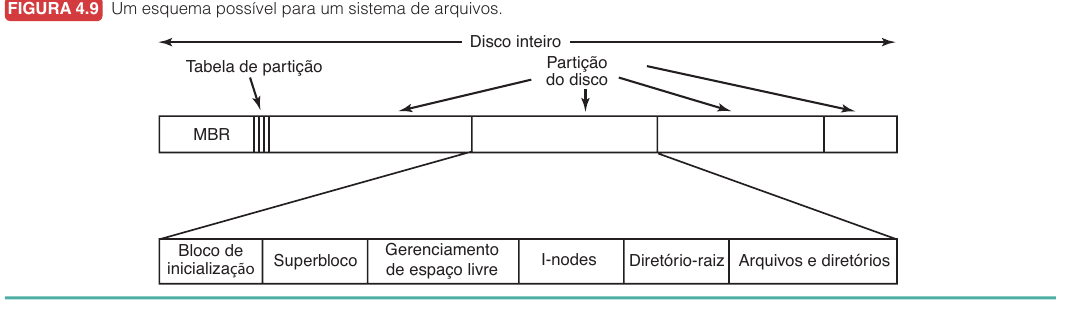
| Estrutura | Papel |
|---|---|
| MBR | Código inicial e tabela de partições |
| Bloco de inicialização | Carrega o SO daquela partição, quando aplicável |
| Superbloco | Parâmetros fundamentais do sistema de arquivos |
| Espaço livre | Informa quais blocos podem ser usados |
| I-nodes | Metadados e endereços dos blocos |
| Diretório-raiz | Ponto inicial da árvore |
| Dados | Arquivos e diretórios |
Superbloco
O superbloco é especialmente importante.
Ele guarda parâmetros essenciais para interpretar a partição.
Se for perdido ou corrompido, o sistema pode não saber:
- tamanho dos blocos
- onde ficam i-nodes
- onde começa a área de dados
- como interpretar o restante da partição
Sem superbloco confiável, o restante do disco pode virar bytes sem contexto.
Alocação Contígua
Cada arquivo ocupa uma sequência contínua de blocos no disco.
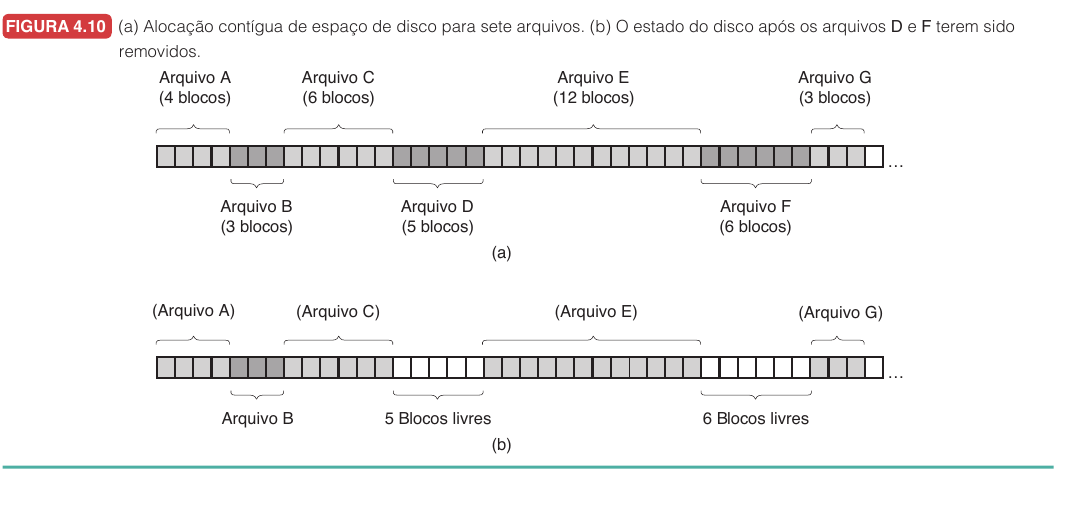
Vantagens:
- simples: basta bloco inicial e tamanho
- leitura sequencial rápida: blocos ficam juntos
Problemas:
- fragmentação externa
- arquivo novo pode não caber em nenhuma lacuna
- crescimento exige prever tamanho ou mover arquivo
Lista Encadeada e FAT
Lista encadeada: cada bloco aponta para o próximo.
Vantagem:
- elimina exigência de blocos contíguos
Problema:
- acesso aleatório é ruim
- para chegar ao bloco $n$, é preciso seguir ponteiros desde o início
FAT melhora isso:
- tabela global do sistema de arquivos
- uma entrada para cada bloco do disco
- entrada $4$ pode dizer que o próximo bloco é $7$
- encadeamento seguido sem ler cada bloco de dados no disco
I-nodes
Em sistemas com i-nodes, cada arquivo possui sua própria estrutura de metadados.
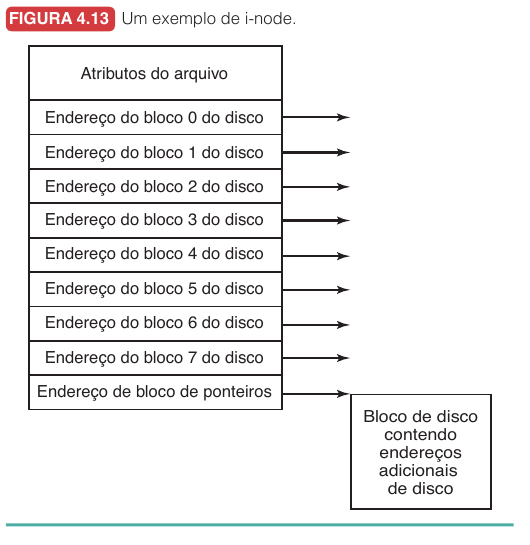
I-nodes
O i-node guarda:
- atributos do arquivo
- endereços dos blocos que pertencem ao arquivo
- ponteiros diretos para blocos de dados
- ponteiros indiretos quando o arquivo cresce
Arquivos pequenos são baratos; arquivos grandes continuam possíveis.
FAT vs I-node
Considere um arquivo nos blocos físicos $4$, $7$ e $12$.
Na FAT:
| Bloco | Próximo |
|---|---|
| $4$ | $7$ |
| $7$ | $12$ |
| $12$ | fim |
No i-node:
| Ponteiro do i-node | Bloco apontado |
|---|---|
| direto 1 | $4$ |
| direto 2 | $7$ |
| direto 3 | $12$ |
Diferença central: FAT é global e indexada por blocos; i-node é por arquivo.
Vantagem do I-node
FAT:
- tabela comum a todos os arquivos
- cresce com o número total de blocos do disco
- precisa ficar disponível na memória para funcionar bem
I-node:
- sistema carrega principalmente os i-nodes dos arquivos abertos
- metadados ficam associados ao próprio arquivo
- escala melhor em discos grandes
Ambos aceitam arquivos espalhados. A diferença é onde fica o mapa dos blocos.
Implementando Diretórios
Diretório precisa mapear nomes para informação que localiza o arquivo.
| Estratégia | Como funciona |
|---|---|
| Atributos na entrada | Entrada guarda nome, atributos e endereços de disco |
| Entrada aponta para i-node | Entrada guarda nome e número do i-node; atributos ficam no i-node |
Nomes longos e variáveis criam desafios:
- reservar 255 caracteres por entrada desperdiça espaço
- sistemas reais usam entradas variáveis ou área separada para nomes
- diretórios grandes podem usar hash ou caches de busca
Gerenciamento de Espaço: Tamanho de Bloco
Arquivos são divididos em blocos de tamanho fixo.
| Bloco pequeno | Bloco grande |
|---|---|
| Desperdiça menos espaço no último bloco | Reduz quantidade de blocos por arquivo |
| Pode exigir mais buscas e metadados | Melhora leitura sequencial |
| Economiza espaço em arquivos pequenos | Pode desperdiçar espaço em arquivos pequenos |
Conflito clássico: espaço vs tempo.
O melhor tamanho depende da carga de trabalho: vídeos grandes e milhões de arquivos pequenos pedem decisões diferentes.
Lista Livre e Mapa de Bits
Para reutilizar espaço, o sistema precisa saber quais blocos estão livres.
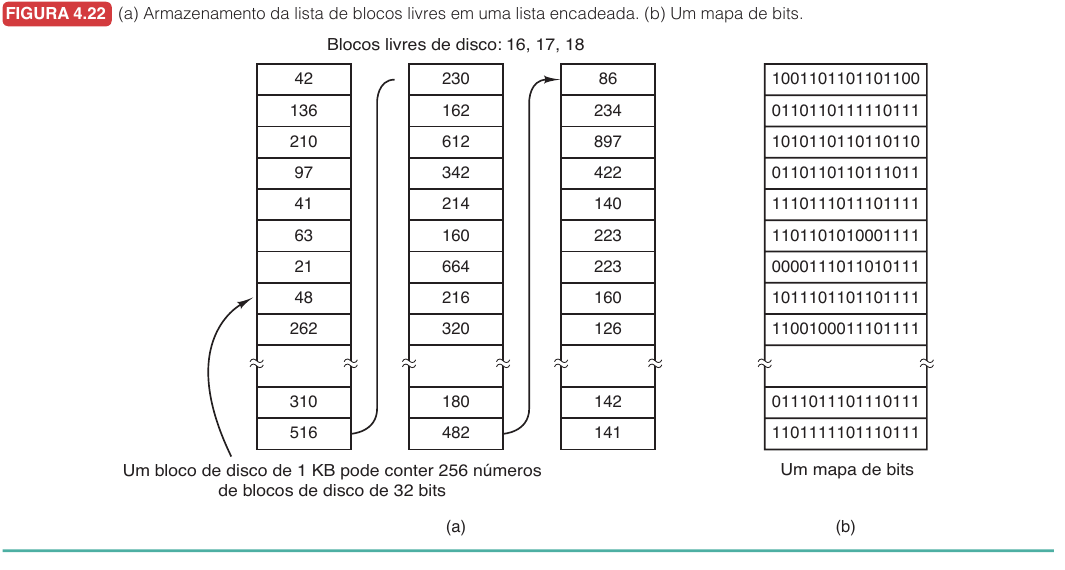
| Técnica | Ideia | Vantagem | Custo |
|---|---|---|---|
| Lista encadeada | Blocos livres listados em estruturas encadeadas | Pode usar os próprios blocos livres | Dificulta encontrar blocos próximos |
| Mapa de bits | Um bit por bloco indica livre ou ocupado | Compacto e facilita achar sequências | Precisa ser mantido e consultado |
Cotas
Em sistemas multiusuário, o SO pode impor cotas.
Cota limita:
- número de blocos por usuário
- número de arquivos por usuário
- consumo total de espaço
Objetivo:
- impedir que um usuário use todo o disco
- proteger os demais usuários
- tornar o uso do armazenamento previsível
Confiabilidade: Por que é Difícil?
Sistemas de arquivos precisam ser rápidos e sobreviver a falhas.
Problema: operações simples exigem várias escritas reais.
Remover arquivo em sistema parecido com UNIX pode exigir:
- remover entrada do diretório
- liberar o i-node
- liberar blocos de dados
Se o sistema cai no meio, estruturas podem discordar entre si.
Falhas Durante Remoção
Se cai depois de remover a entrada do diretório:
- arquivo não aparece mais
- blocos podem continuar marcados como ocupados
- há vazamento de espaço
Se cai depois de liberar blocos, mas antes de remover a entrada:
- entrada de diretório ainda parece válida
- blocos podem ser reutilizados por outro arquivo
- risco de corrupção séria
Consistência exige coordenar várias estruturas.
Verificação de Consistência
Ferramentas como fsck examinam redundâncias do sistema de arquivos.
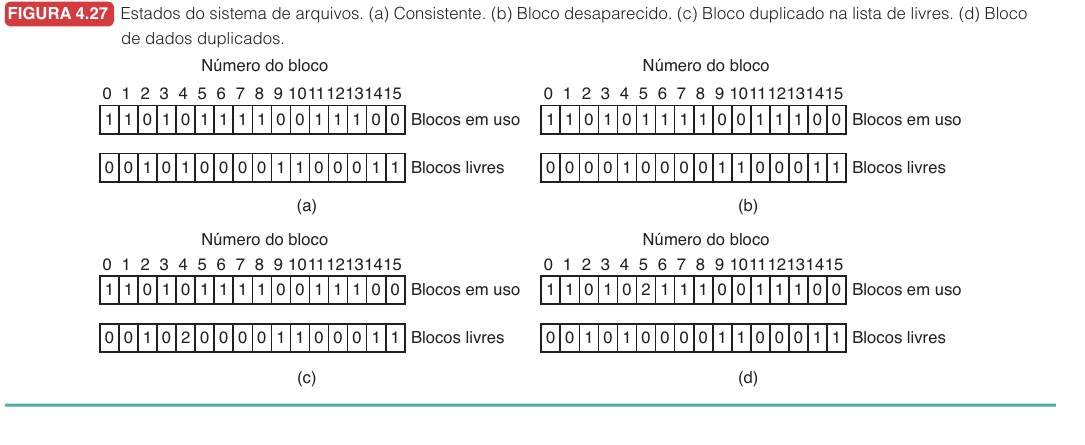
Podem encontrar:
- blocos desaparecidos
- blocos duplicados na lista livre
- blocos de dados atribuídos a mais de um arquivo
Funciona, mas pode ser lento em discos grandes porque precisa varrer muitas estruturas.
Journaling
Sistema com journaling registra no diário o que pretende fazer antes de modificar estruturas principais.
Exemplo: remover temp.log.
transação: remover temp.log
ação 1: remover entrada do diretório
ação 2: liberar i-node k
ação 3: marcar blocos b1, b2, b3 como livres
Depois que a entrada está segura no disco, o sistema executa as ações reais.
Após queda, a recuperação lê o journal e sabe o que completar ou verificar.
Journaling: Cuidados
Operações registradas precisam ser idempotentes.
Idempotente: pode ser repetida sem mudar o resultado além da primeira execução.
Exemplo: marcar bloco $n$ como livre só é seguro se repetir isso não adicionar o mesmo bloco duas vezes a uma lista.
Journaling não é backup:
- ajuda após queda ou desligamento inesperado
- não protege contra apagar arquivo por engano
- não protege contra sobrescrever dados importantes
- não protege contra perda física do disco
Sistemas Estruturados em Log
Tanenbaum também discute sistemas de arquivos estruturados em log.
Ideia:
- escrever muitas alterações pequenas como grandes segmentos sequenciais
- aproveitar melhor a largura de banda do disco
- útil quando muitas leituras já são atendidas pela cache
Diferença para journaling:
| Técnica | Ideia principal |
|---|---|
| Sistema estruturado em log | Organizar o disco como grande log para melhorar escrita |
| Journaling | Registrar intenções para recuperar consistência após falha |
Desempenho: Cache de Blocos
Disco é muito mais lento que memória.
Mesmo com alta taxa de transferência, há latência de busca, rotação, fila e controlador.
Cache de blocos:
- mantém em RAM blocos logicamente pertencentes ao disco
- leitura em cache evita acesso ao disco
- bloco ausente é lido do disco e guardado para o futuro
Cache: Desempenho vs Risco
Algoritmos como LRU podem decidir quais blocos remover.
Mas sistemas de arquivos têm preocupação extra: consistência.
Blocos críticos:
- i-nodes
- diretórios
- mapas de espaço livre
- superblocos
Se metadados sujos ficam só na cache e o sistema cai, o sistema de arquivos pode ficar inconsistente.
Política de cache não é apenas desempenho; também é risco.
Políticas de Escrita
| Estratégia | Ideia | Consequência |
|---|---|---|
| Escrita adiada | Junta alterações e grava depois | Melhora desempenho, aumenta risco de perda recente |
| Escrita direta | Grava blocos modificados imediatamente | Mais segurança, mais E/S |
sync periódico | Força blocos sujos para o disco em intervalos | Limita janela de perda |
| Journaling | Registra transações antes de aplicar mudanças | Recupera consistência mais rápido |
Não existe política grátis: reduzir risco costuma custar desempenho.
Leitura Antecipada e Localidade
Leitura antecipada:
- se o arquivo está sendo lido sequencialmente, carrega o próximo bloco antes do pedido
- ajuda em vídeo, logs e arquivos grandes
- atrapalha em acesso aleatório se desperdiça cache e largura de banda
Localidade:
- colocar blocos relacionados próximos reduz movimento do braço do disco
- melhora leitura sequencial em HDs
Desfragmentação:
- tenta tornar arquivos e espaço livre mais contíguos
SSD Muda Parte da História
Em SSDs:
- não há braço mecânico
- não há latência rotacional
- fragmentação tem impacto diferente
- desfragmentar geralmente não traz ganho relevante
- desfragmentar ainda gasta ciclos de escrita do dispositivo
Conclusão: otimizações pensadas para HDs nem sempre fazem sentido em SSDs.
Entrada e Saída: Caminho até o Hardware
O sistema de arquivos depende de E/S.
Para ler um bloco, ele conversa com camadas mais baixas que sabem lidar com:
- controladores
- interrupções
- DMA
- dispositivos reais
Tanenbaum divide dispositivos em duas categorias principais.
| Tipo | Característica | Exemplos |
|---|---|---|
| Bloco | Blocos endereçáveis independentemente | Disco, SSD, Blu-ray, pendrive |
| Caractere | Fluxo de caracteres ou bytes | Teclado, impressora, mouse, serial |
Controladores e Registradores
Dispositivo possui parte física e parte eletrônica.
A parte eletrônica é o controlador.
O SO geralmente conversa com o controlador, não com cada detalhe físico.
Controlador expõe registradores para:
- enviar comandos
- consultar estado
- transferir dados
- verificar erros
Exemplo: perguntar se o dispositivo está pronto ou mandar iniciar uma leitura.
E/S Mapeada em Memória
Há duas formas clássicas de acessar registradores de dispositivos.
| Abordagem | Como funciona |
|---|---|
| Espaço de E/S separado | Instruções especiais acessam portas de E/S |
| E/S mapeada em memória | Registradores aparecem como endereços de memória |
Na E/S mapeada em memória, driver acessa registradores como posições especiais de memória.
Cuidado: registradores de dispositivo não devem ser tratados como memória comum em cache.
Cache poderia devolver valor antigo e esconder mudança real do dispositivo.
E/S Programada, Interrupções e DMA
| Técnica | Quem faz o trabalho | Vantagem | Problema |
|---|---|---|---|
| E/S programada | CPU verifica e transfere dados | Simples | Pode desperdiçar CPU em espera ocupada |
| Interrupção | Dispositivo interrompe quando precisa de atenção | Libera CPU entre eventos | Muitas interrupções custam caro |
| DMA | Controlador transfere entre dispositivo e memória | Reduz cópias e interrupções | Exige hardware e coordenação |
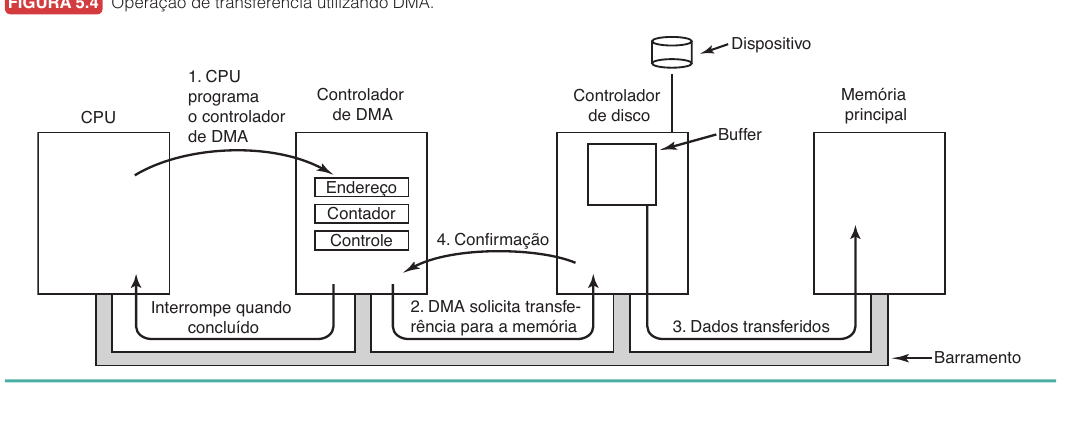
Como o DMA Funciona
No DMA, a CPU programa o controlador com:
- endereço de memória
- tamanho da transferência
- direção da transferência
Depois:
- controlador move dados entre dispositivo e memória
- CPU executa outro trabalho
- CPU é interrompida quando a transferência termina
DMA é especialmente útil para transferências maiores.
Exemplo: Impressora
Imagine imprimir uma sequência de caracteres.
| Método | O que acontece |
|---|---|
| E/S programada | CPU envia um caractere e fica perguntando se a impressora aceita o próximo |
| Interrupção | CPU envia um caractere e faz outra coisa; impressora interrompe quando pronta |
| DMA | CPU prepara um buffer; controlador transfere e interrompe apenas ao final |
Interrupção não é gratuita:
- salva estado
- troca contexto
- executa tratador
- retorna
Se ocorrer a cada byte, pode ficar cara.
Camadas do Software de E/S
Cada camada esconde detalhes da camada inferior e oferece interface mais regular para a superior.
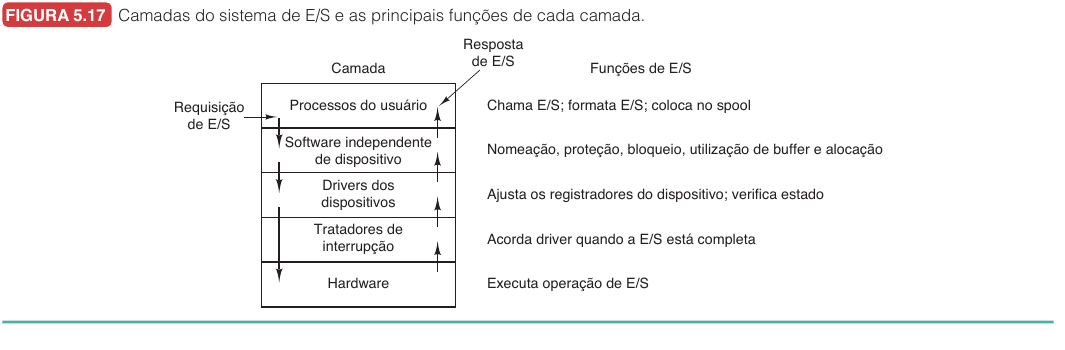
| Camada | Responsabilidade |
|---|---|
| Processo do usuário | Chama E/S, formata dados, usa bibliotecas e spooling |
| Software independente | Nomeia dispositivos, protege acesso, gerencia buffer |
| Driver | Traduz operações abstratas em comandos do controlador |
| Tratador de interrupção | Acorda driver ou processo quando operação termina |
| Hardware | Executa operação física |
Independência de Dispositivo
Um programa que chama read não deveria saber se os dados vêm de:
- SSD
- HD
- pendrive
- sistema de arquivos remoto
Drivers contêm conhecimento específico do dispositivo:
- blocos, filas, controladores, erros e comandos para discos
- eventos de teclas para teclados
Drivers podem ser carregados dinamicamente.
O restante do kernel não deve ser reescrito para cada dispositivo novo.
Software Independente, Buffers e Spooling
Software independente de dispositivo cuida de:
- nomeação uniforme
- proteção
- utilização de buffers
- relatório de erros
- alocação e liberação de dispositivos dedicados
- tamanho de bloco lógico independente do dispositivo
No UNIX, dispositivos aparecem como arquivos especiais em /dev.
Buffers suavizam diferenças de velocidade entre produtor e consumidor.
Spooling coloca trabalhos em fila para dispositivos dedicados, como impressoras.
O Caminho Completo de uma Leitura
Quando um processo executa read(fd, buffer, n):
- chamada de biblioteca aciona chamada de sistema
- kernel localiza arquivo aberto associado a
fd - sistema de arquivos descobre blocos da posição atual
- cache de blocos é consultada
- se há cache hit, dados são copiados ao processo
- se há cache miss, camada de E/S busca o bloco
- driver programa controlador, possivelmente com DMA
- processo pode bloquear
- interrupção avisa fim da E/S
- bloco chega à cache e dados retornam ao processo
Próximos Passos
Avaliação C3!