Introdução8.1
Hoje veremos como o sistema operacional organiza o espaço onde os processos vivem: a memória principal.
Até aqui, tratamos processos como se cada um tivesse apenas uma sequência de instruções, alguns registradores e um estado no escalonador. Essa visão é útil, mas incompleta. Um processo também precisa de memória para código, variáveis globais, pilha, heap, bibliotecas e buffers de entrada e saída. Se dois processos enxergassem a memória física diretamente, um erro simples de ponteiro poderia sobrescrever dados de outro processo ou até do próprio sistema operacional.
O problema central desta aula é este: como permitir que vários programas coexistam na RAM sem que um destrua o espaço do outro?
Esta aula usa como base o Tanenbaum, capítulo 3, seções 3.1 e 3.2, páginas 125 a 133. Tanenbaum apresenta esse tema começando pelo caso mais simples, sem abstração de memória, e só depois introduz a ideia de espaço de endereçamento. Vamos seguir essa progressão porque ela revela por que a abstração é necessária.
Se um programa em C acessa por engano uma posição de memória fora do vetor, por que isso não deveria permitir que ele altere variáveis de outro programa aberto no computador?
Sem abstração de memória8.2
A forma mais simples de usar memória é não ter abstração nenhuma. O programa trabalha diretamente com endereços físicos. Se ele lê o endereço 1000, está lendo a posição física 1000 da RAM. Se escreve no endereço 2000, modifica a posição física 2000.
Essa ideia parece natural em sistemas muito simples. Um microcontrolador pequeno, um sistema embarcado mínimo ou um computador antigo executando um único programa podem funcionar assim. O programa ocupa a memória, usa os dispositivos e não precisa dividir a RAM com aplicações concorrentes.
O problema aparece quando queremos multiprogramação. Se vários processos ficam na memória ao mesmo tempo, cada um não pode simplesmente usar os mesmos endereços físicos.
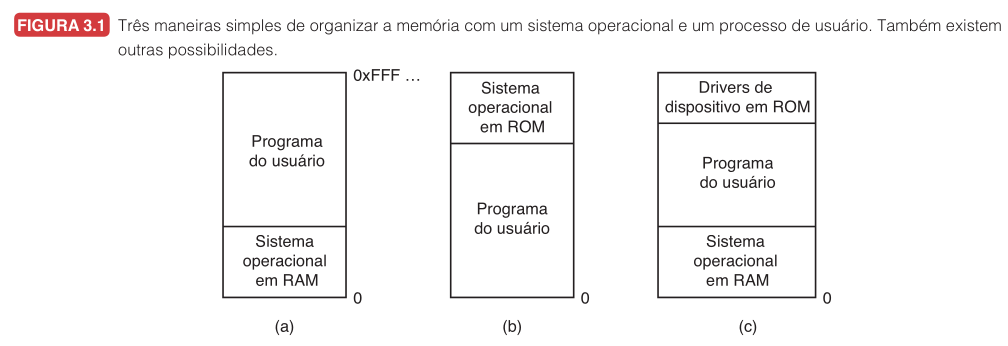
Tanenbaum abre o capítulo com as três organizações mais simples para esse cenário sem abstração. Em todas elas, o processo de usuário acessa endereços físicos diretamente, mas o sistema operacional pode estar posicionado de maneiras diferentes.
| Organização | No livro | Quem usa | Risco principal |
|---|---|---|---|
| SO em RAM baixa | Figura 3.1(a) | Computadores de grande porte antigos | Um erro do usuário pode sobrescrever o SO. |
| SO em ROM alta | Figura 3.1(b) | Portáteis e sistemas embarcados simples | Pouco flexível para cargas variáveis. |
| Drivers em ROM, SO em RAM | Figura 3.1(c) | Primeiros PCs (ex: MS-DOS com BIOS) | Um programa ainda pode danificar a parte do SO em RAM. |
Nessas três organizações, tipicamente apenas um processo executa por vez. O usuário digita um comando, o SO copia o programa do disco para a memória e o executa. Quando o processo termina, o SO exibe o prompt de novo e o ciclo recomeça. Para executar múltiplos programas, é possível salvar o conteúdo da memória em disco e carregar o programa seguinte, mas isso já antecipa o conceito de swapping.
Essa organização funciona quando o software é conhecido de antemão, como em um eletrodoméstico ou dispositivo simples. Ela continua comum em sistemas embarcados e cartões inteligentes. Mas ela não é adequada para um computador de propósito geral onde usuários abrem programas independentes.
Considere dois programas compilados como se começassem no endereço físico $0$.
| Programa | Endereço esperado | Conteúdo |
|---|---|---|
| Editor de texto | $0$ a $999$ | código e dados do editor |
| Navegador | $0$ a $1999$ | código e dados do navegador |
Se os dois forem carregados literalmente a partir do endereço $0$, eles se sobrepõem. O segundo programa sobrescreve parte do primeiro.
O erro não está no código do editor nem no código do navegador. O erro está na ausência de uma camada que permita que cada programa tenha sua própria visão de memória.
Sem abstração, surgem dois problemas fundamentais.
| Problema | O que significa | Consequência |
|---|---|---|
| Realocação | O programa pode ser carregado em posições diferentes da RAM. | Endereços internos precisam continuar fazendo sentido. |
| Proteção | Um processo não deve acessar memória de outro processo ou do núcleo. | Acesso indevido precisa ser bloqueado. |
Esses dois problemas explicam por que a gerência de memória não é apenas uma tabela de espaços livres. Ela é uma parte essencial da segurança e da ilusão de isolamento entre processos.
Por que proteção sozinha não resolve8.2.1
Uma solução histórica foi usada nos primeiros modelos IBM 360. A memória era dividida em blocos de 2 KB, e cada bloco recebia uma chave de proteção de 4 bits armazenada em registradores especiais na CPU. O processo em execução também tinha uma chave associada, guardada na PSW (Palavra de Estado do Programa). O hardware impedia que um processo acessasse blocos com chave diferente, e só o SO podia modificar essas chaves.
Essa estratégia garante a proteção: um processo não consegue escrever sobre áreas de outro. Mas ela não resolve o problema completo, como Tanenbaum demonstra com o exemplo da Figura 3.2.
Considere dois programas de 16 KB compilados como se começassem no endereço $0$.
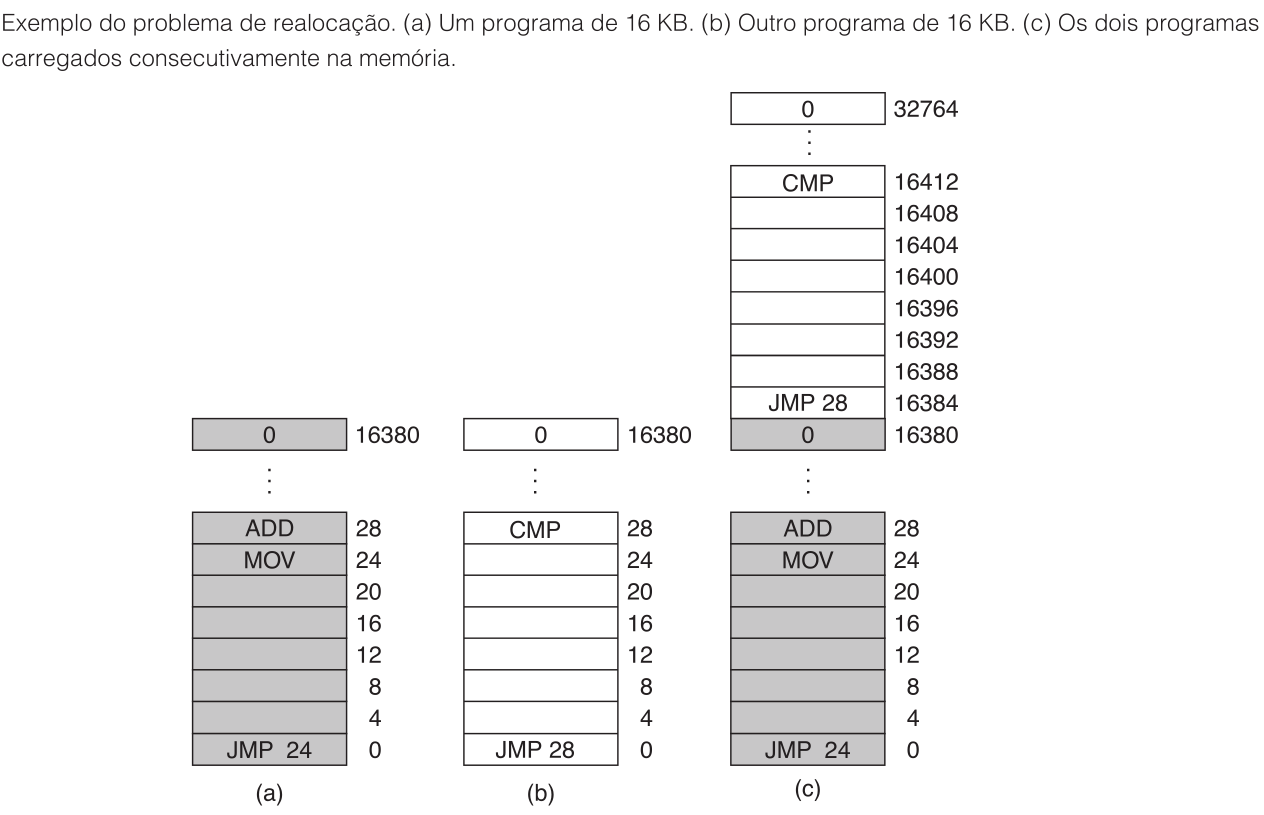
O primeiro programa começa com um salto JMP 24 e o segundo com JMP 28. Se o primeiro for carregado na base $0$ e o segundo na base $16384$, a instrução JMP 28 do segundo programa deveria significar "vá para o endereço 28 dentro do meu próprio espaço". Mas o hardware interpreta $28$ como endereço físico absoluto. Resultado: o segundo programa salta para dentro do primeiro, provavelmente colapsando em menos de um segundo.
As chaves de proteção impedem escrita indevida, mas não corrigem automaticamente os endereços internos do programa. O problema que as chaves não resolvem é justamente a realocação: fazer com que endereços como $28$ e $24$ apontem para o lugar certo quando o programa é carregado em uma posição diferente.
Uma tentativa de corrigir isso é a realocação estática. Durante o carregamento, o sistema soma a base de carga a cada endereço usado pelo programa. Assim, JMP 28 vira JMP 16412 (pois $16384 + 28 = 16412$). O IBM 360 usava essa técnica como solução provisória.
O problema é que o carregador precisa saber quais valores são endereços e quais são constantes comuns. Na Figura 3.2, o valor $28$ no segundo programa deve ser realocado, mas uma instrução como MOV REGISTER1, 28 contém um $28$ que é apenas um valor literal, não um endereço. Realocar tudo cegamente quebraria o programa. Além disso, o processo de realocação durante a carga torna a inicialização mais lenta e exige que o executável indique quais posições contêm endereços.
Proteger impede que um processo acesse áreas proibidas. Realocar garante que os endereços internos do programa façam sentido quando ele é carregado em outra posição da memória. Um sistema correto precisa resolver as duas coisas.
Multiprogramação e uso da CPU8.2.2
Por que manter vários processos na memória ao mesmo tempo? Porque processos frequentemente bloqueiam esperando entrada e saída. Enquanto um processo espera disco, rede ou teclado, outro pode usar a CPU.
Tanenbaum modela essa intuição com uma ideia simples. Se um processo passa uma fração $p$ do tempo esperando E/S, então a probabilidade de todos os $n$ processos estarem esperando ao mesmo tempo é aproximadamente $p^n$. Logo, uma estimativa de utilização da CPU é:
$$ U = 1 - p^n $$
Essa fórmula não pretende descrever todos os detalhes de um sistema real. Ela serve para mostrar a força da multiprogramação: quanto mais processos independentes estão residentes, menor a chance de a CPU ficar sem nada para fazer.
Suponha que cada processo passe $80\%$ do tempo esperando E/S. Nesse caso, $p = 0{,}8$.
Com apenas um processo:
$$ U = 1 - 0{,}8^1 = 0{,}2 $$
A CPU fica ocupada cerca de $20\%$ do tempo.
Com quatro processos:
$$ U = 1 - 0{,}8^4 = 1 - 0{,}4096 = 0{,}5904 $$
A utilização sobe para aproximadamente $59\%$.
O ganho aparece porque é improvável que todos estejam esperando E/S exatamente ao mesmo tempo.
Aumentar o número de processos residentes melhora a chance de manter a CPU ocupada, mas não cria memória infinita. Em algum ponto, a RAM acaba, a troca com disco aumenta e o sistema pode ficar mais lento.
Espaços de endereçamento8.3
A abstração central da gerência de memória é o espaço de endereçamento. Em vez de entregar endereços físicos diretamente ao processo, o sistema permite que cada processo enxergue uma coleção própria de endereços.
Um processo pode acreditar que sua memória começa em $0$, mesmo que, fisicamente, ele esteja carregado a partir do endereço $12000$ da RAM. O endereço que o programa gera é chamado de endereço lógico ou endereço virtual. O endereço efetivamente usado na RAM é o endereço físico.
Se dois processos usam internamente o endereço lógico $100$, por que isso não significa que ambos acessarão a mesma posição física da RAM?
Base e limite8.3.1
Agora chegamos à solução que Tanenbaum apresenta como clássica: dois registradores especiais de hardware, chamados de base e limite. Essa técnica, usada em máquinas como o CDC 6600 e o Intel 8088, implementa realocação dinâmica de forma simples.
O registrador base guarda o endereço físico onde o programa começa na memória. O registrador limite guarda o comprimento do programa. A cada acesso à memória, o hardware da CPU automaticamente adiciona o valor da base ao endereço gerado pelo processo, antes de enviá-lo ao barramento. Ao mesmo tempo, confere se o endereço oferecido é menor que o valor do registrador limite; se não for, gera uma falta e aborta o acesso.
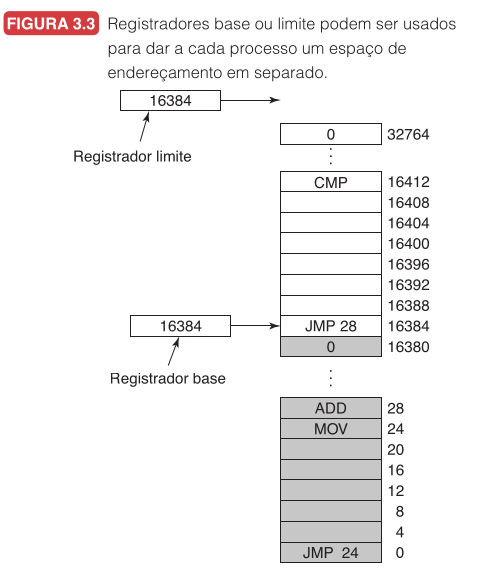
$$ \text{endereço físico} = \text{base} + \text{endereço lógico} $$
desde que:
$$ 0 \leq \text{endereço lógico} < \text{limite} $$
Um processo tem:
$$ base = 10000 $$
$$ limite = 4000 $$
Se ele acessa o endereço lógico $350$, o acesso é válido porque $350 < 4000$. O endereço físico será:
$$ 10000 + 350 = 10350 $$
Se ele tenta acessar o endereço lógico $5000$, o acesso é inválido porque $5000 \geq 4000$. O sistema deve bloquear a operação.
Essa técnica resolve realocação e proteção ao mesmo tempo.
| Necessidade | Como base e limite ajudam |
|---|---|
| Realocação | O mesmo programa pode ser carregado em outro ponto da RAM mudando apenas a base. |
| Proteção | O limite impede que o processo saia da sua região. |
Quando o escalonador troca de processo, o sistema operacional também troca os valores de base e limite. Assim, cada processo passa a enxergar seu próprio espaço.
Considere dois processos:
| Processo | Base | Limite | Endereço lógico acessado | Endereço físico |
|---|---|---|---|---|
| $P_1$ | $10000$ | $4000$ | $120$ | $10120$ |
| $P_2$ | $30000$ | $4000$ | $120$ | $30120$ |
Os dois usam o mesmo endereço lógico $120$, mas acessam posições físicas diferentes. Essa é a essência do isolamento por espaço de endereçamento.
A tradução de endereços precisa ocorrer em todo acesso à memória. Por isso ela não pode ser feita lentamente por software comum. O hardware de gerência de memória, normalmente chamado de MMU, executa essa tradução e verifica proteção durante a execução.
Também existe um custo nessa simplicidade. Com base e limite, todo acesso à memória exige pelo menos uma comparação e uma soma. A comparação verifica se o endereço lógico está dentro do limite. A soma adiciona a base para produzir o endereço físico. Comparações são rápidas, mas adições podem ser lentas por causa do tempo de propagação do transporte (carry-propagation time). Em máquinas modernas isso é resolvido com circuitos de adição especializados, mas a observação é importante: abstrações de memória têm custo e precisam ser implementadas com cuidado.
Em muitas implementações, os registradores base e limite são protegidos para que apenas o SO possa modificá-los. O CDC 6600 tinha essa proteção; o Intel 8088 não tinha nem registrador limite. Ele tinha múltiplos registradores base, permitindo realocar código e dados independentemente, mas sem oferecer proteção contra referências além dos limites.
Swapping8.4
Mesmo com espaços de endereçamento, a RAM continua sendo finita. Se há mais processos ativos do que memória disponível, o sistema pode mover temporariamente um processo inteiro para o disco e trazer outro para a RAM. Essa técnica é chamada de swapping (troca de processos).
A ideia é simples. Um processo bloqueado ou ocioso pode sair da memória principal. Seu conteúdo é salvo em disco. Mais tarde, quando ele precisar executar novamente, o sistema o carrega de volta para a RAM.
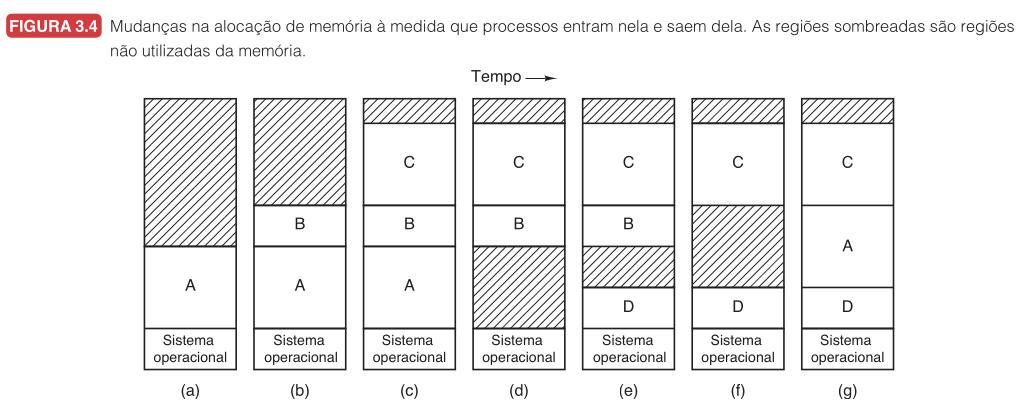
A Figura 3.4 do Tanenbaum ilustra essa dinâmica. De início, só o processo A está na memória. Depois B e C são criados ou trazidos do disco. Em seguida, A é devolvido ao disco e D entra. Por fim, B sai e A volta, mas em uma posição diferente. Quando A retorna, os endereços dentro dele precisam ser realocados, seja por software durante a carga, seja pelo hardware durante a execução (registradores base e limite funcionam bem aqui).
Swapping aumenta a flexibilidade, mas tem custo alto. Disco é muito mais lento que RAM. Se o sistema começa a gastar tempo demais movendo processos para dentro e para fora da memória, a máquina parece travar mesmo que a CPU esteja tecnicamente ativa.
Imagine uma máquina com $8$ GB de RAM executando três processos grandes:
| Processo | Memória necessária | Estado |
|---|---|---|
| Editor de vídeo | $5$ GB | ativo |
| Navegador | $3$ GB | ativo |
| Jogo | $4$ GB | aberto em segundo plano |
Os três juntos exigem $12$ GB. Como a RAM não comporta tudo ao mesmo tempo, o sistema pode retirar temporariamente o jogo da RAM e gravá-lo na área de swap. Quando o usuário volta para o jogo, ele precisa ser trazido novamente.
O usuário percebe isso como uma demora grande na troca de janelas.
O disco permite sobreviver a picos de uso, mas não substitui RAM. Quando o sistema depende demais de swap, o gargalo passa a ser a movimentação de dados entre memória e disco.
Tanenbaum chama atenção para um detalhe prático. Sistemas comuns podem iniciar dezenas de processos de fundo logo após ligar, antes mesmo de o usuário abrir um aplicativo. Cada processo pode consumir vários megabytes. Aplicações pesadas podem consumir centenas de megabytes ou gigabytes. Por isso, manter todos os processos completamente residentes o tempo todo muitas vezes não é viável.
Quando o swapping cria vários buracos na memória, uma ideia natural é compactar a memória, movendo processos para juntar todos os espaços livres em uma região maior. Essa ideia funciona conceitualmente, mas é cara. Tanenbaum dá uma ordem de grandeza: em uma máquina com $16$ GB, mesmo copiando $8$ bytes a cada $8$ ns, compactar toda a memória levaria cerca de $16$ segundos.
Crescimento dos processos8.5
Um processo nem sempre mantém o mesmo tamanho durante toda a execução. A pilha pode crescer com chamadas de função. O heap pode crescer com alocações dinâmicas. Bibliotecas podem ser carregadas sob demanda. Buffers podem aumentar.
Isso cria uma dificuldade prática. Se o processo foi colocado em uma lacuna de memória exatamente do seu tamanho inicial, não haverá espaço para crescer.
Há algumas respostas possíveis:
- reservar espaço extra ao carregar o processo,
- mover o processo para uma lacuna maior,
- recusar a alocação se não houver espaço,
- usar técnicas mais avançadas, como memória virtual com paginação, que veremos depois.
O ponto importante é que gerenciar memória não é apenas encontrar uma posição inicial. O sistema precisa lidar com mudanças ao longo do tempo.
Tanenbaum destaca dois crescimentos típicos dentro do processo. O segmento de dados, usado por alocação dinâmica, costuma crescer para cima. A pilha, usada por chamadas de função, variáveis locais e endereços de retorno, costuma crescer para baixo.
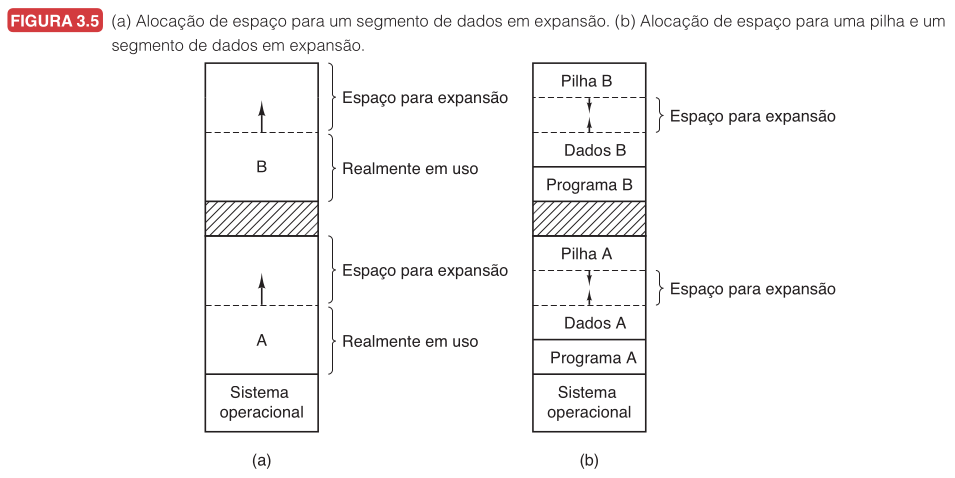
A Figura 3.5(a) mostra uma configuração com espaço de crescimento reservado para cada processo. A Figura 3.5(b) mostra uma alternativa: cada processo tem uma pilha no topo da sua região, crescendo para baixo, e um segmento de dados logo após o programa, crescendo para cima. A memória entre eles pode ser usada por qualquer um dos dois.
Se esse espaço interno acaba, o sistema precisa mover o processo para uma região maior, trocar o processo para o disco até existir espaço suficiente ou encerrar a execução.
Quando um processo é transferido para o disco, Tanenbaum observa que apenas a memória realmente em uso deve ser copiada, levar junto o espaço extra de crescimento seria desperdício.
Gerenciamento de memória livre8.6
Quando processos entram e saem da RAM, surgem lacunas livres espalhadas. O sistema operacional precisa saber quais partes da memória estão ocupadas e quais estão disponíveis.
Tanenbaum apresenta duas formas clássicas de representar essa informação: mapas de bits e listas encadeadas.
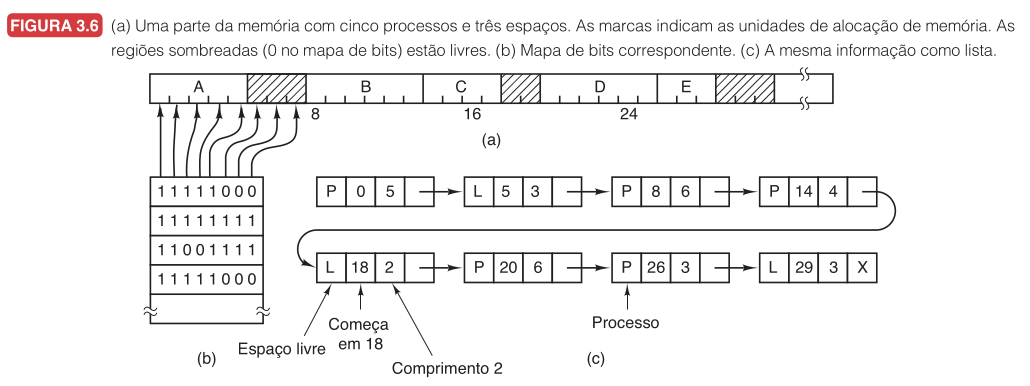
A Figura 3.6 mostra as três representações lado a lado: (a) a memória com cinco processos e três lacunas, (b) o mapa de bits correspondente e (c) a mesma informação como lista encadeada.
Mapa de bits8.6.1
No mapa de bits, a memória é dividida em unidades de alocação, que podem ser tão pequenas quanto algumas palavras ou tão grandes quanto vários kilobytes. Cada unidade recebe um bit: $0$ para livre, $1$ para ocupado.
O tamanho da unidade de alocação é uma decisão importante. Unidades pequenas (como 4 bytes) reduzem desperdício no último bloco de cada processo, mas aumentam o tamanho do mapa. Com uma unidade de 4 bytes, o mapa ocupa $1/32$ da memória total. Unidades grandes reduzem o mapa, mas aumentam o desperdício na última unidade de cada processo.
O principal problema do mapa de bits é a busca. Para carregar um processo que precisa de $k$ unidades contíguas, o sistema precisa encontrar $k$ bits $0$ consecutivos. Procurar uma sequência longa em um mapa de bits é uma operação lenta, especialmente porque a sequência pode ultrapassar os limites de palavras no mapa.
Considere a memória dividida em blocos de mesmo tamanho.
| Bloco | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Estado | ocupado | ocupado | livre | livre | ocupado | livre | livre | livre |
| Bit | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
Se um processo precisa de três blocos contíguos, o sistema procura três zeros consecutivos. Nesse exemplo, os blocos $5$, $6$ e $7$ servem.
Lista encadeada de segmentos8.6.2
Outra estratégia é manter uma lista encadeada de trechos livres e ocupados. Cada entrada na lista especifica se o trecho é um espaço livre (L) ou está alocado a um processo (P), o endereço onde começa, seu comprimento e um ponteiro para o próximo item.
Quando a lista é mantida ordenada por endereço, liberar memória fica mais simples. O sistema olha os vizinhos do segmento recém-liberado. Há quatro combinações possíveis, ilustradas na Figura 3.7 do Tanenbaum.
Uma lista de memória pode ser representada assim:
| Tipo | Início | Tamanho |
|---|---|---|
| Processo $P_1$ | $0$ | $100$ |
| Livre | $100$ | $50$ |
| Processo $P_2$ | $150$ | $80$ |
| Livre | $230$ | $120$ |
Se $P_2$ termina, sua região vira livre. Como há uma lacuna livre logo depois dele, o sistema deve unir os dois espaços:
| Tipo | Início | Tamanho |
|---|---|---|
| Processo $P_1$ | $0$ | $100$ |
| Livre | $100$ | $50$ |
| Livre | $150$ | $200$ |
Depois da fusão, a lista correta fica:
| Tipo | Início | Tamanho |
|---|---|---|
| Processo $P_1$ | $0$ | $100$ |
| Livre | $100$ | $250$ |
A fusão evita que a memória pareça mais fragmentada do que realmente está.
Quando a lista é mantida ordenada por endereço, liberar memória fica mais simples. O sistema olha os vizinhos do segmento recém-liberado. Há quatro combinações possíveis, ilustradas na Figura 3.7 do Tanenbaum.
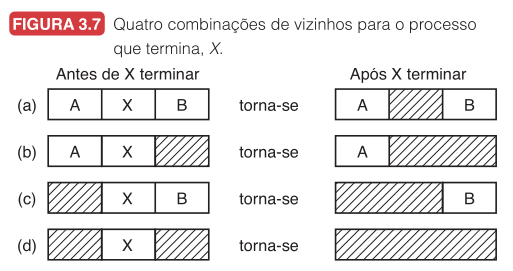
| Vizinho anterior | Vizinho seguinte | Ação | Entradas na lista |
|---|---|---|---|
| Processo | Processo | Apenas troca o tipo de P para L. | Nenhuma mudança no número de entradas. |
| Livre | Processo | Funde com a lacuna anterior. | Uma entrada a menos. |
| Processo | Livre | Funde com a lacuna seguinte. | Uma entrada a menos. |
| Livre | Livre | Funde as três regiões em uma única lacuna. | Duas entradas a menos. |
Uma lista duplamente encadeada facilita essa fusão porque permite encontrar rapidamente o vizinho anterior. Como a entrada da tabela de processos do processo que está terminando geralmente aponta para a entrada da lista do próprio processo, o encadeamento duplo torna a fusão mais conveniente.
Algoritmos de alocação8.7
Quando um novo processo precisa entrar na memória (ou um que estava em disco precisa voltar), o sistema precisa escolher uma lacuna livre para ele. Essa escolha afeta diretamente a fragmentação e o desempenho. Tanenbaum descreve cinco algoritmos.
Antes de ver os algoritmos: se você precisasse guardar caixas de tamanhos diferentes em um depósito com prateleiras de vários tamanhos, como escolheria onde colocar cada caixa? Tentaria a primeira que coubesse, a que encaixasse mais justa ou a maior de todas?
First fit (primeiro encaixe)8.7.1
O gerenciador de memória percorre a lista de segmentos até encontrar o primeiro espaço livre que seja grande o suficiente. O espaço é então dividido em duas partes: uma para o processo e outra para o que sobrou (a menos que o encaixe seja exato).
Passo a passo:
- Comece no início da lista de segmentos.
- Examine cada entrada, se for um espaço livre e tiver tamanho $\geq$ o necessário, pare a busca.
- Se o espaço for exatamente do tamanho pedido, entregue-o inteiro ao processo.
- Se o espaço for maior, divida-o: a parte de tamanho exato vai para o processo e a sobra permanece como lacuna livre.
- Se nenhum espaço for suficiente, o processo precisa esperar (ou provocar swapping).
É o algoritmo mais rápido porque a busca termina assim que encontra o primeiro encaixe. Como efeito colateral, tende a concentrar processos no início da memória e lacunas maiores no final.
Next fit (próximo encaixe)8.7.2
Funciona como o first fit, com uma diferença: ele memoriza a posição onde parou na busca anterior. Da próxima vez, começa dali em vez de recomeçar do início.
Passo a passo:
- Mantenha um ponteiro indicando a última posição onde um espaço foi alocado.
- Na próxima alocação, inicie a busca a partir desse ponteiro.
- Percorra a lista circularmente até encontrar um espaço livre adequado.
- Se der a volta completa sem encontrar, o processo precisa esperar.
A intenção é não concentrar toda a atividade no início da lista. Porém, simulações de Bays (1977) mostram que o next fit tem desempenho ligeiramente pior que o first fit.
Best fit (melhor encaixe)8.7.3
Percorre a lista inteira, do início ao fim, e escolhe o menor espaço livre que seja grande o suficiente para o processo. A ideia é encontrar um encaixe quase exato para não desperdiçar espaço.
Passo a passo:
- Inicialize uma variável com o melhor candidato como "nenhum".
- Percorra toda a lista de segmentos.
- Para cada lacuna livre com tamanho $\geq$ o necessário, compare com o melhor candidato atual.
- Se for menor que o melhor candidato atual (e ainda couber), atualize o candidato.
- Ao final da lista, se houver candidato, aloque ali.
- Se não houver nenhum espaço suficiente, o processo espera.
O best fit é mais lento que o first fit porque sempre percorre a lista inteira. Surpreendentemente, ele também tende a gerar mais desperdício: ao escolher a lacuna que encaixa mais justa, sobra um pedaço minúsculo que provavelmente nunca será usado para nada.
Worst fit (pior encaixe)8.7.4
Escolhe a maior lacuna disponível. A intuição é que, pegando a maior lacuna, a sobra ainda será grande o suficiente para ser útil em alocações futuras.
Passo a passo:
- Inicialize o maior candidato como "nenhum".
- Percorra toda a lista de segmentos.
- Para cada lacuna livre, se for maior que o maior candidato atual, atualize-o, mas apenas se também couber o processo.
- Ao final, aloque na maior lacuna encontrada.
Apesar de parecer engenhoso, simulações mostram que o worst fit também não é uma boa ideia na prática.
Quick fit (encaixe rápido)8.7.5
Mantém listas separadas para tamanhos comuns de alocação, por exemplo, uma lista para lacunas de 4 KB, outra para 8 KB, outra para 12 KB e assim por diante.
Passo a passo:
- Mantenha uma tabela com $n$ entradas, cada uma apontando para uma lista de lacunas de um tamanho específico.
- Quando um processo solicitar $k$ KB, vá direto para a lista correspondente (ou a mais próxima acima de $k$).
- Se houver uma lacuna nessa lista, aloque e divida se necessário.
- Se a lista estiver vazia, tente listas de tamanhos maiores.
- Se nenhuma lista tiver lacuna suficiente, o processo espera.
Encontrar um espaço é extremamente rápido para tamanhos comuns. O problema é a liberação: quando um processo termina, o sistema precisa descobrir quem são os vizinhos para fundir lacunas. Isso é muito mais caro com listas separadas. Se a fusão não for feita, a memória se fragmenta rapidamente em muitos pedaços pequenos.
Considere as lacunas livres abaixo, nessa ordem:
$$ 50\text{ KB},\ 120\text{ KB},\ 70\text{ KB},\ 300\text{ KB} $$
Um processo precisa de $65$ KB.
| Algoritmo | Lacuna escolhida | Sobra |
|---|---|---|
| First fit | $120$ KB | $55$ KB |
| Best fit | $70$ KB | $5$ KB |
| Worst fit | $300$ KB | $235$ KB |
O best fit parece ótimo porque desperdiça pouco naquele instante. Mas a sobra de $5$ KB talvez seja pequena demais para usos futuros. Esse é o tipo de decisão local que pode piorar o estado global da memória.
Tanenbaum observa que todos os quatro primeiros algoritmos podem ser acelerados mantendo listas separadas para processos e lacunas livres. Assim, a busca por espaço percorre apenas lacunas, ignorando processos. O custo aparece na liberação: o segmento precisa sair da lista de processos, entrar na lista de livres e talvez ser fundido com vizinhos.
Quando a lista de lacunas é mantida separada e ordenada por tamanho, o best fit fica mais rápido: ele simplesmente percorre do menor para o maior e para no primeiro que couber. Nesse caso, first fit e best fit se tornam igualmente rápidos, e next fit perde o sentido.
Fragmentação8.7.6
Fragmentação é o desperdício causado pela forma como a memória foi dividida.
| Tipo | Onde está o desperdício | Exemplo |
|---|---|---|
| Fragmentação interna | Dentro de uma área alocada. | O processo recebe $64$ KB, mas usa $60$ KB. |
| Fragmentação externa | Entre áreas alocadas. | Há $100$ KB livres no total, mas quebrados em lacunas pequenas. |
Um processo precisa de $90$ KB. A memória livre total é $120$ KB, distribuída assim:
$$ 40\text{ KB},\ 30\text{ KB},\ 50\text{ KB} $$
Apesar de haver $120$ KB livres ao todo, nenhuma lacuna isolada comporta o processo. Esse é um caso de fragmentação externa.
Uma solução possível seria compactar a memória, movendo processos para juntar os espaços livres. Mas compactação custa tempo e exige realocação segura.
Para compactar, o sistema precisa mover processos na memória e ajustar as traduções de endereço. Isso pode ser caro, especialmente se feito com frequência.
Gerenciar memória é criar a ilusão de que cada processo tem seu próprio espaço contínuo e protegido, mesmo quando a RAM física é compartilhada, limitada e fragmentada.
Questões8.8
1. Qual é o principal problema de executar vários programas sem abstração de memória?
- A) A CPU não consegue alternar entre processos.
- B) Todos os programas precisam ser escritos em assembly.
- C) Processos podem sobrescrever a memória uns dos outros ou do sistema operacional.
- D) O disco deixa de poder ser usado para E/S.
2. Explique a diferença entre endereço lógico e endereço físico.
3. Um processo possui $base = 5000$ e $limite = 2000$. Para cada endereço lógico abaixo, diga se o acesso é válido e, se for, calcule o endereço físico.
- a) $100$
- b) $1999$
- c) $2000$
- d) $2500$
4. Por que os registradores de base e limite ajudam tanto na realocação quanto na proteção?
5. Se um processo passa $70\%$ do tempo esperando E/S, estime a utilização da CPU com $3$ processos residentes usando $U = 1 - p^n$.
6. O que é swapping? Por que ele melhora a flexibilidade do sistema, mas pode degradar muito o desempenho?
7. Diferencie mapa de bits e lista encadeada como formas de gerenciar memória livre.
8. Considere lacunas livres de $40$ KB, $100$ KB, $60$ KB e $200$ KB, nessa ordem. Um processo precisa de $55$ KB. Qual lacuna seria escolhida por first fit, best fit e worst fit?
9. Diferencie fragmentação interna e fragmentação externa com um exemplo para cada.
10. Um sistema possui $150$ KB livres no total, distribuídos em lacunas de $30$ KB, $50$ KB e $70$ KB. Um processo precisa de $100$ KB. Ele pode ser carregado em memória contígua sem compactação? Justifique.
11. Por que o crescimento do heap ou da pilha pode complicar a alocação de processos em memória contígua?
12. Em uma frase, explique por que a gerência de memória é também um mecanismo de segurança.
13. Por que uma técnica de proteção por chaves, como a usada no IBM 360, não resolve sozinha o problema de executar dois programas compilados para começar no endereço $0$?
14. Em uma lista de segmentos ordenada por endereço, um processo termina e seus dois vizinhos imediatos são lacunas livres. O que o sistema deve fazer com essas três regiões?
15. Qual é a principal vantagem do quick fit e qual é seu principal custo quando processos terminam ou são transferidos para o disco?
16. Descreva o passo a passo do algoritmo best fit. Por que, apesar de procurar o encaixe mais justo, ele tende a gerar mais desperdício que o first fit?
17. Qual é a diferença entre first fit e next fit? O next fit resolve qual possível problema do first fit?
1. C.
2. Endereço lógico é o endereço gerado pelo programa dentro do seu espaço de endereçamento. Endereço físico é a posição real acessada na RAM depois da tradução feita pelo hardware e pelo sistema operacional.
3. a) válido, endereço físico $5100$. b) válido, endereço físico $6999$. c) inválido, pois o limite permite endereços de $0$ até $1999$. d) inválido.
4. A base permite carregar o mesmo processo em diferentes posições físicas sem reescrever todos os seus endereços. O limite impede acessos fora da região autorizada.
5. $U = 1 - 0{,}7^3 = 1 - 0{,}343 = 0{,}657$. A utilização estimada é de aproximadamente $65{,}7\%$.
6. Swapping é mover temporariamente processos entre RAM e disco. Ele permite executar mais processos do que caberiam simultaneamente na RAM, mas pode ser muito lento porque disco é muito mais lento que memória principal.
7. No mapa de bits, cada unidade de memória é representada por um bit livre ou ocupado. Na lista encadeada, a memória é representada por segmentos com tipo, início e tamanho.
8. First fit escolhe $100$ KB. Best fit escolhe $60$ KB. Worst fit escolhe $200$ KB.
9. Fragmentação interna ocorre quando há sobra dentro de uma área alocada. Fragmentação externa ocorre quando há memória livre total suficiente, mas dividida em lacunas pequenas demais.
10. Não. Há $150$ KB livres no total, mas a maior lacuna tem apenas $70$ KB. Sem compactação ou outra técnica, o processo de $100$ KB não cabe em memória contígua.
11. Porque o processo pode precisar de mais espaço depois de carregado. Se não houver lacuna adjacente livre, o sistema precisa mover o processo, reservar folga antecipadamente ou negar a alocação.
12. Porque ela impede que um processo acesse ou modifique regiões de memória pertencentes a outros processos ou ao núcleo.
13. Porque a chave de proteção impede acessos indevidos, mas não muda os endereços internos do programa. Se o segundo programa contém um salto para $28$, esse valor ainda pode ser interpretado como endereço físico absoluto, saltando para dentro de outro programa.
14. Deve fundir a lacuna anterior, o segmento recém-liberado e a lacuna seguinte em uma única lacuna maior.
15. A vantagem é encontrar rapidamente lacunas de tamanhos comuns por meio de listas separadas. O custo é que, ao liberar memória, fica mais caro localizar vizinhos e fundir lacunas, aumentando o risco de fragmentação se a fusão não for feita.
16. Best fit: percorre toda a lista do início ao fim, guarda o menor espaço livre que seja $\geq$ ao pedido e aloca nele. Gera mais desperdício porque a sobra costuma ser minúscula e inútil, lacunas pequenas demais para qualquer alocação futura.
17. First fit sempre recomeça do início da lista; next fit continua de onde parou na busca anterior. O next fit tenta evitar que o início da lista concentre toda a atividade e se fragmente mais rápido que o resto.
Próximos passos8.9
Vimos como o SO organiza o espaço de memória para múltiplos processos usando realocação, proteção, swapping e algoritmos de alocação. Em aulas futuras, exploraremos a memória virtual com paginação, que elimina a exigência de regiões contíguas e permite executar programas maiores que a RAM física.