Introdução5.1
A análise léxica trata da formação das estruturas básicas de uma comunicação, na linguagem normalmente se tratam de palavras, dessa forma, essa etapa estudaria como elas se formam e as regras que devem ser respeitadas para construirmos palavras válidas no português, tais como divisão silábica, acentuação e afins.
Nas linguagens de compilação, entretanto, essa etapa é um pouco diferente, felizmente, bem mais simples do que na língua portuguesa. Aqui estudaremos como o código e separado nos blocos que chamamos de tokens para que possamos criar as regras de interpretação na próxima etapa de análise (análise sintática).
Dessa forma, nesse capítulo aprenderemos como definir e diferenciar os conceitos de lexema, padrão e tokens, assim como compreender as principais técnicas para leitura dos caracteres do nosso código.
Funções do Analisador Léxico5.2
A analise léxica é a entrada do nosso compilador, dessa maneira, executa algumas tarefas simples mas que são essenciais para transformarmos aglomerados de caracteres escritos em um arquivo de texto qualquer em estruturas de dados computáveis. Notem que por convenção colocamos .c, .cpp, .java no arquivos de código, contudo, no fim são apenas texto como qualquer outro arquivo .txt. Portanto, nessa etapa estaremos focados em 4 etapas, sendo elas:
- Ler os caracteres do código-fonte.
- Remover espaços em branco, tabulações (
\tab, tab) e comentários.
- Remover espaços em branco, tabulações (
- Agrupar os caracteres em lexemas e classificá-los.
- Detectar erros e relacionar com a posição no programa.
- Gerar a lista de tokens (ou marcas).
- Manipular a tabela de símbolos.
Uma decisão arquitetural crítica na construção de compiladores é definir como o Scanner se comunica com a próxima fase, a Análise Sintática (ou Parser). Uma abordagem ingênua seria projetar o Scanner para ler todo o arquivo de uma vez e gerar uma lista gigante contendo todos os tokens do programa. Contudo, uma vez que um código com erro sintático na primeira linha só acusaria erro sintático após ler todos os caracteres nessa abordagem, a prática adotada foi a abordagem orientada à demanda.
Nesse modelo, o Analisador Sintático atua como o "maestro" da compilação. Quando ele precisa verificar a próxima regra gramatical, ele solicita ao Scanner apenas o próximo pedaço de informação através de uma operação geralmente chamada de get_next_token. O Scanner, então, lê o arquivo apenas o suficiente para montar um único token, entrega-o ao Parser e pausa sua execução esperando a próxima chamada da função.
Essa estratégia é vital para a eficiência do sistema. Imagine que exista um erro de sintaxe logo na primeira linha de um arquivo de um milhão de linhas. Se o Scanner processasse todo o arquivo antes de qualquer análise, teríamos desperdiçado tempo computacional analisando 999.999 linhas inutilmente. Na abordagem sob demanda, o erro é detectado imediatamente na primeira solicitação e o processo é abortado, economizando recursos preciosos.
Definições5.3
Para construir um Scanner robusto, precisamos de precisão terminológica absoluta. Um erro muito comum é confundir o texto lido com a sua classificação abstrata. Para evitar isso, definimos três conceitos distintos:
Lexema5.3.1
O lexema é o conteúdo propriamente dito. Ele se refere à sequência exata de caracteres encontrada no código-fonte. Por exemplo, ao digitar while, contador ou 3.14, essas strings específicas são os lexemas. É o que está "escrito no papel".
Problema: Dado o código na linguagem C apresentado logo abaixo, defina os lexemas correspondentes:
int x = 42;
Os lexemas são:
- int
- x
- =
- 42
- ;
Padrão (Pattern)5.3.2
O padrão é a regra de formação dos elementos. Ele descreve a forma genérica que um lexema deve ter para ser aceito em uma determinada categoria. Geralmente, utilizamos expressões regulares para definir essas regras. Por exemplo, o padrão para um identificador pode ser definido como "deve começar com uma letra, seguida de zero ou mais letras ou dígitos".
Ao final dessa aula iremos ver melhor como podemos montar e representar nossos lexemas com esses padrões, entretanto, já devem ter visto algo na disciplina de autômatos finitos.
Token5.3.3
O token é o produto final empacotado. Trata-se de uma estrutura de dados, geralmente um par <tipo, valor>, que categoriza o lexema processado. Onde tipo é o tipo de token e o valor é o lexema associado. Vejamos alguns exemplos:
- Para uma variável com nome "x" teríamos o token
<IDENT, "x">, onde IDENT indica um token do tipo identificador e o literal (string constante) "x" indica o lexema (valor do token); - Para um literal de número, teríamos
<NUM, 42>.
Note que IDENT e NUM são nomes arbitrários escolhidos na hora de programar o compilador. Entretanto, sempre teremos algo semelhante para números, identificadores, operadores aritméticos, booleanos e afins.
Vejamos agora uma tabela com alguns exemplos das três definições lado a lado.
| Token | Padrão (Informal) | Exemplos de Lexemas |
|---|---|---|
| if | caracteres i, f | if |
| else | caracteres e, l, s, e | else |
| comparison | < ou > ou <= ou >= ou == ou != |
<, =, != |
| id | letra seguida por letras e dígitos | pi, score, D2 |
| number | qualquer constante numérica | 3, 0, 6.02e23 |
| literal | qualquer caractere diferente de ", cercado por "s |
"core dumped" |
Alguns tokens comuns na maioria das linguagens são:
- Um token para cada palvra-chave.
- Tokens para os operadores (individuais ou em classes).
- Um token para todos os identificadores.
- Tokens para classes de constantes (ex. números e literais).
- Um token para cada símbolo de pontuação (parênteses, vírgula, ponto, ponto e vírgula, etc).
Engenharia de Entrada: Buffering5.4
A função mais básica do Scanner é a leitura de caracteres. No entanto, ler o disco rígido (HDD ou SSD) byte a byte é uma operação proibitivamente lenta devido à latência do hardware. O sistema operacional é otimizado para entregar blocos grandes de dados (por exemplo, 4KB) de uma só vez. Para alinhar a velocidade extrema da CPU com a relative lentidão do disco, utilizamos técnicas de Buffering.
Entretanto, note que em algumas situações é necessário um look-a-head para ter certeza que o token terminou (exemplos da soma e do operador de >). Dessa forma é como a utilização de sentinelas ao final de cada buffer. Isso evita que o Scanner tenha que verificar a cada caractere se chegou ao fim do buffer.
Antes de vermos os problemas o buffering gera, vamos buscar entender como esse processo é feito em um formato de leitura mais simples, para a leitura de uma linha completa. Veja a imagem abaixo onde temos uma linha somando duas variáveis junto de dois sentinelas, um marcando o início do token e outro o final dele.
Entretanto, em alguns cenários, uma linha pode ser pouco dado e ficar buscando no HD várias linhas o tempo todo não é eficiente, por esse motivo utilizamos o buffering. Entretanto, aqui temos o desafio que chamamos de Problema da Fronteira do Buffer. Imagine que carregamos um bloco de dados na memória e o lexema while está posicionado exatamente no final desse bloco, dividido entre o fim de uma leitura e o início da próxima. O Scanner lê w, h, i e o buffer acaba. Se carregarmos o próximo bloco imediatamente sobre o atual para ler o resto, perderemos o início da palavra que estava no bloco anterior.
Para resolver isso, utilizamos a técnica de Pares de Buffers (Buffer Pairs). Dividimos a área de memória disponível em duas metades lógicas. Carregamos a primeira metade e processamos. Quando o ponteiro de leitura atinge o final da primeira metade, carregamos a segunda metade sem apagar a primeira. Isso garante que um lexema que cruza a fronteira esteja sempre contíguo na memória lógica do Scanner.
Note que essa abordagem ainda pode dar problemas caso o token seja muito grande e ocupe os dois buffers, o que aconteceria muito se utilizássemos um tamanho de três para cada buffer como no exemplo acima, entretanto, nos compiladores esses buffers são bem maiores (4 Kb), fazendo com que esses problemas quase não aconteçam.
Problema: Um Scanner utiliza um sistema de Buffer Duplo onde cada metade tem tamanho de 4 bytes. O código fonte a ser lido é: int x = 10;. Simule o estado dos buffers no momento em que o token x é processado.
O código fonte completo é: i, n, t, , x, , =, , 1, 0, ;
O sistema operacional preenche o Buffer A com os primeiros 4 bytes.
- Buffer A:
['i', 'n', 't', ' '] - Buffer B:
[]
- Buffer A:
O Scanner lê
int. Isso ocorre porque o próximo caractere é um espaço<INT>gerado.O Scanner consome o espaço. O ponteiro agora está no final do Buffer A.
O Scanner atinge o limite. O sistema carrega os próximos 4 bytes no Buffer B.
- Buffer A:
['i', 'n', 't', ' '](Mantido) - Buffer B:
['x', ' ', '=', ' ']
- Buffer A:
O Scanner lê
xno início do Buffer B. Ele verifica o próximo caracterexé um identificador.O Scanner lê
=no Buffer B até encontrar o próximo espaço, concluindo que é um operador de atribuição e não de igualdade.
Esse processo irá se repetir começando novamente no buffer A agora, onde colocaremos o número 10 junto com o ponto e vírgula (;) totalizando três dos 4 bytes, de forma que, iremos gerar o token de literal numérico e o de final de linha.
Tabela de Símbolos5.5
A tabela de símbolos é uma das estruturas mais importantes de um compilador. Apesar dessa importância, ela não é complexa nem difícil de compreender. Seu funcionamento é semelhante ao de um dicionário presente em diversas linguagens de programação, cuja função é relacionar nome, chamados identificadores, a números.
Esses identificadores podem representar nomes de variáveis, funções ou outros elementos da linguagem. Importante notar que eles não são palavras reservadas. A tabela de símbolos mapeia esses nomes arbitrários para números inteiros, permitindo que o compilador utilize esses números como referências internas para manipular os identificadores. A utilidade prática desse mecanismo ficará mais clara posteriormente.
Entretanto, por hora, para facilitar a compreensão, realizaremos um processo de tokenização em alto nível, no qual serão gerados os tokens do código-fonte e as variáveis identificadas serão inseridas na tabela de símbolos correspondente.
Problema: Considere o código na linguagem C abaixo e preencha a tabela de símbolos e monte a lista de tokens gerados para o código.
int a = 10;
int b = 4;
float c = a / b;
printf("%f", c);
Durante o processo de análise léxica, o código-fonte é lido sequencialmente, da esquerda para a direita e de cima para baixo. Cada sequência válida de caracteres é reconhecida como um lexema e classificada em um token, que é inserido na lista de tokens gerados pelo analisador léxico. Esse processo ocorre para todas as ocorrências, inclusive quando um mesmo identificador aparece várias vezes no código.
Quando um lexema do tipo identificador é reconhecido, o analisador léxico consulta a tabela de símbolos para verificar se esse identificador já foi inserido anteriormente. Caso o identificador ainda não exista, ele é adicionado à tabela e recebe um identificador numérico único. Se o identificador já estiver presente, como ocorre com o identificador a na expressão c = a / b, um novo token é gerado e inserido na lista de tokens, porém nenhuma nova entrada é criada na tabela de símbolos. Assim, a tabela de símbolos mantém apenas uma entrada por identificador, enquanto a lista de tokens reflete todas as suas ocorrências no código.
<KEYWORD, int>
<ID, 0>
<OP_ASSIGN, =>
<NUM, 10>
<DELIM, ;>
<KEYWORD, int>
<ID, 1>
<OP_ASSIGN, =>
<NUM, 4>
<DELIM, ;>
<KEYWORD, float>
<ID, 2>
<OP_ASSIGN, =>
<ID, 0>
<OP_ARIT, />
<ID, 1>
<DELIM, ;>
<ID, 3>
<DELIM, (>
<LITERAL, "%f">
<DELIM, ,>
<ID, 2>
<DELIM, )>
<DELIM, ;>
A tabela de símbolos contém apenas identificadores e não permite duplicatas.
| ID | Identificador |
|---|---|
| 0 | a |
| 1 | b |
| 2 | c |
| 3 | printf |
Portanto, a lista de tokens registra todas as ocorrências dos lexemas reconhecidos no código, enquanto a tabela de símbolos armazena cada identificador apenas uma única vez. Identificadores reutilizados, como a, b e c, geram novos tokens sempre que aparecem no código, mas são apenas consultados (lookup) na tabela de símbolos, sem que novas entradas sejam criadas. Esse mecanismo garante eficiência e consistência na representação dos nomes durante as etapas posteriores do compilador.
Notem que a lista de tokens são uma representação completa do nosso código até o momento, devemos ser capazes de com essa lista, junto da tabela de símbolos, estruturar novamente nosso código original. Mais para frente na disciplina iremos aprender à melhorar essa representação estrutural do código.
Expressões Regulares5.6
Como vimos, as linguagens de programação são Linguagens Formais. Para descrever, de forma precisa e sem ambiguidades, os padrões aceitos pelo Scanner, utilizamos a álgebra das Expressões Regulares (Regex). As expressões regulares operam sobre um Alfabeto, que é um conjunto finito de símbolos permitidos (como ASCII ou Unicode), para formar Cadeias, isto é, palavras ou sequências específicas de caracteres.
As operações fundamentais que permitem construir qualquer padrão léxico, mesmo os mais complexos, são apenas três:
- União ( | ): Representa a escolha ou alternância. A expressão
a | bsignifica “o caractereaOU o caractereb”. - Concatenação ( ): Não possui símbolo explícito ou é representada apenas por um espaço. Indica sequência. A expressão
absignifica “aseguido imediatamente porb”. - Fechamento de Kleene (*): Representa repetição. A expressão
a*significa “zero ou mais ocorrências dea”.
A partir dessas primitivas, derivamos operadores de conveniência que são amplamente utilizados na construção de compiladores:
- Fechamento Positivo (+): Equivale a
aa*(uma ou mais ocorrências). É essencial para a definição de números, pois um número não pode ter zero dígitos. - Opcionalidade (?): Indica zero ou uma ocorrência. É muito útil para representar sinais (
+ou-) ou partes fracionárias de números. - Classes de Caracteres ([ ]): Funcionam como uma abreviação para a união de vários caracteres. Por exemplo,
[abc] = a | b | c. Também podem ser usadas para intervalos, como[a-z] = a | b | c | ... | z. É possível combinar múltiplos intervalos, como em[a-zA-Z0-9], que representa todas as letras minúsculas, todas as letras maiúsculas e os 10 dígitos numéricos. - Negação de Classes ([^ ]): Muitas vezes, é mais prático definirmos o que não queremos aceitar. Ao inserirmos o acento circunflexo (
^) como o primeiro caractere dentro de colchetes, invertemos a lógica da classe. Por exemplo,[^0-9]reconhece qualquer caractere que não seja um dígito. Essa construção é vital para definirmos strings, onde precisamos ler "aspas, seguidas de qualquer coisa que não seja aspas, seguidas de aspas". A expressão ficaria:"[^"]*".
Além disso, existem algumas convenções importantes. Como expressões regulares são amplamente utilizadas em programação, adotaremos convenções comuns em códigos.
A primeira delas é o uso do caractere ponto (.) com o significado de “qualquer caractere”. Nesse contexto, ele representa qualquer símbolo, desde letras e números até caracteres especiais, como o menos (-) e a divisão (/). Caso seja desejado utilizar o ponto como um caractere literal, e não como esse curinga, devemos precedê-lo de um caractere de escape (\). Da mesma forma, se quisermos utilizar o próprio caractere de escape, ele também deve ser escapado (\\), como é comum em linguagens de programação.
Além disso, utilizaremos o símbolo $\epsilon$ para representar o vazio, ou seja, a ausência de caracteres. A utilidade desse símbolo será explorada mais adiante, especialmente nas aulas sobre gramática e análise sintática, mas já é importante introduzi-lo neste momento.
Por fim, o espaço em branco nas regras é ignorado. Portanto, caso seja necessário representar explicitamente um espaço, utilizamos aspas duplas. Da mesma forma, quando desejamos representar uma cadeia específica de caracteres, ela também deve ser colocada entre aspas duplas. Se for necessário utilizar aspas duplas como parte da cadeia, devemos empregar o caractere de escape. A seguir, veremos um exemplo de como escrever expressões regulares para representar diferentes elementos léxicos.
Problema: Considere os seguintes elementos léxicos de uma linguagem de programação simples:
- Identificadores
- Números inteiros
- Operadores de atribuição (
=) e soma (+)
- Defina uma expressão regular para cada um desses elementos.
- Explique, em palavras, o que cada expressão regular representa.
- Mostre exemplos de lexemas válidos reconhecidos por cada expressão.
Para resolver esse problema, precisamos primeiro identificar claramente quais são as regras de formação de cada elemento léxico e, em seguida, traduzi-las para expressões regulares utilizando os operadores e convenções já apresentados.
Começamos pelos identificadores. Em muitas linguagens de programação, um identificador deve iniciar obrigatoriamente com uma letra e pode ser seguido por letras ou dígitos. Essa regra evita ambiguidades com números e facilita o reconhecimento léxico. Para representar essa estrutura, utilizamos uma classe de caracteres para letras, seguida de outra classe que permite letras ou dígitos repetidas vezes. Assim, a expressão regular para identificadores pode ser escrita como:
- Identificador:
[a-zA-Z][a-zA-Z0-9]*
Essa expressão indica que o primeiro caractere deve ser uma letra (minúscula ou maiúscula) e que ele pode ser seguido de zero ou mais letras ou dígitos. Exemplos de lexemas válidos reconhecidos por esse padrão são x, contador, A1 e var123.
Em seguida, analisamos os números inteiros. Um número inteiro é formado por um ou mais dígitos consecutivos. Como um número não pode ser vazio, utilizamos o fechamento positivo para garantir pelo menos um dígito. A expressão regular correspondente é:
- Número inteiro:
[0-9]+
Essa expressão representa uma sequência de um ou mais dígitos numéricos. Exemplos de lexemas válidos são 0, 7, 42 e 123456.
Por fim, temos os operadores, que neste caso são símbolos simples e individuais. Como eles não possuem variação interna, suas expressões regulares são diretas e correspondem exatamente ao caractere desejado:
- Atribuição:
= - Soma:
+
Essas expressões reconhecem exclusivamente os lexemas = e +, respectivamente, sem permitir nenhuma outra variação.
Concluindo, ao definir expressões regulares para cada tipo de token, o analisador léxico consegue identificar corretamente os lexemas presentes no código-fonte, classificá-los em tokens adequados e fornecer essas informações às próximas etapas do compilador. Esse exercício ilustra como regras simples podem ser combinadas para formar a base da análise léxica de uma linguagem de programação.
Analisadores Manuais vs Analisadores Automáticos5.7
Existem diversas ferramentas amplamente conhecidas para a criação de scanners (analisadores léxicos) baseados em expressões regulares. Na prática, o processo funciona da seguinte forma: inicialmente, descrevemos uma expressão regular para cada token válido da linguagem. Em seguida, essas expressões são transformadas em autômatos finitos não determinísticos (AFND) por meio do algoritmo de Thompson.
Posteriormente, aplica-se o algoritmo de subconjuntos (ou powerset) para converter o AFND em um autômato finito determinístico (AFD). Após essa conversão, são utilizados algoritmos de minimização com o objetivo de reduzir o número de estados do autômato, tornando-o mais eficiente.
Ao final desse processo, obtemos um autômato finito determinístico minimizado que lê o código-fonte caractere por caractere, avançando entre estados. Sempre que o autômato alcança um estado final, ele reconhece um token correspondente. Após o reconhecimento, o autômato retorna ao estado inicial e o processo se repete até que todos os caracteres da entrada sejam consumidos.
A seguir, é mostrado um exemplo de autômato finito capaz de reconhecer os seguintes tokens da linguagem: chaves { e }, operador de igualdade ==, operadores relacionais maior >, menor <, maior ou igual >=, menor ou igual <=, operador de negação !, operador de diferença != e operador de atribuição =.
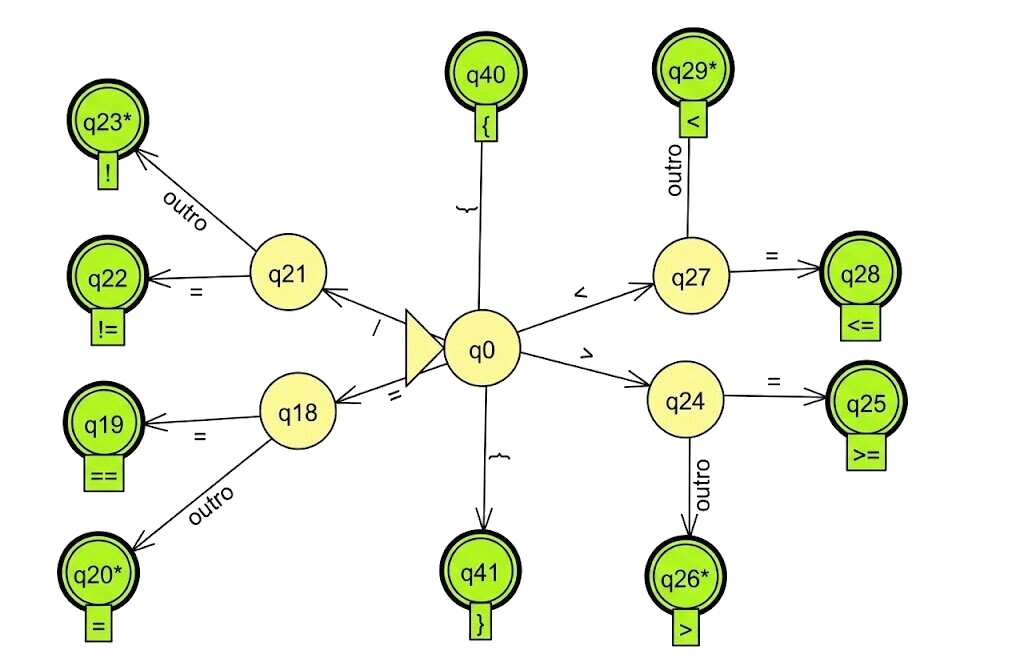
Embora ferramentas baseadas em expressões regulares e geração automática de autômatos facilitem significativamente a construção de analisadores léxicos, compiladores modernos frequentemente utilizam scanners implementados manualmente. Apesar de exigirem mais trabalho e cuidado no desenvolvimento, esses scanners feitos à mão oferecem maior controle sobre o processo de análise léxica, permitindo otimizações específicas, tratamento mais preciso de erros, melhor integração com a tabela de símbolos e maior flexibilidade para lidar com particularidades da linguagem. Além disso, essa abordagem possibilita decisões mais refinadas sobre desempenho, consumo de memória e estratégias de recuperação de erros, fatores essenciais em compiladores reais e de larga escala.
Note que esses analisadores léxicos gerados com autômatos rapidamente crescem em número de estados dificultando muito a adição e refatoração do código final.
Iremos utilizar um scanner manual, não por ele ser mais complexo, mas justamente pelo contrário. Como trabalharemos com uma linguagem reduzida, essa abordagem torna-se mais simples do que o uso de ferramentas automáticas, além de nos permitir compreender claramente como um scanner é implementado. O fato de a linguagem ser mais restrita e com fins educativos reduz significativamente as dificuldades, tornando o processo mais didático e transparente.
Questões5.8
- Considere o trecho de código:
if (score >= 100) return;.
(a) Identifique os lexemas presentes nesta linha.
(b) Classifique cada lexema em seu respectivo token (ex: Palavra-chave, Identificador, Operador, Delimitador, Numeral).
(c) Explique a diferença entre o lexemascoree o padrão (pattern) que define um identificador.
- No texto, discutimos a abordagem orientada à demanda (get_next_token) versus a abordagem de processamento em lote (ler o arquivo todo de uma vez). Explique como a abordagem orientada à demanda economiza recursos computacionais no caso de um erro de sintaxe encontrado logo no início de um arquivo de código extenso.
- O uso de buffers de entrada é essencial para a eficiência de leitura do disco.
(a) Descreva o "Problema da Fronteira do Buffer" e como a técnica de Pares de Buffers soluciona essa questão.
(b) Qual é a função dos caracteres sentinelas inseridos ao final de cada bloco de buffer?
- Descreva, em português, quais tipos de cadeias de caracteres são aceitas pelas seguintes expressões regulares:
(a)a(a|b)*a
(b)(0|1)*111(0|1)*
(c)[A-Z][a-z]*
- Escreva uma expressão regular para reconhecer identificadores que devem obrigatoriamente começar com um sublinhado
_, seguido por pelo menos uma letra maiúscula, podendo terminar com qualquer combinação de letras ou dígitos.
Exemplos válidos:_A,_Var1,_X99.
Exemplos inválidos:var1,_1var,_a.
- Utilizando as definições de
dígitocomo[0-9], escreva uma expressão regular que reconheça números de ponto flutuante (reais). A expressão deve cobrir os seguintes casos:- Obrigatório ter pelo menos um dígito antes do ponto.
- Obrigatório ter o ponto decimal
. - Obrigatório ter pelo menos um dígito após o ponto.
- O número pode ser opcionalmente precedido por um sinal de
+ou-. - Dica: Lembre-se de escapar o ponto decimal se necessário.
- Escreva uma expressão regular para reconhecer números literais no formato hexadecimal típicos da linguagem C.
- Regra: Deve começar com
0x. - Seguido por um ou mais caracteres que podem ser dígitos (
0-9) ou letras deaaf(maiúsculas ou minúsculas).
- Regra: Deve começar com
- O texto menciona que, embora ferramentas automáticas baseadas em autômatos finitos (como Lex/Flex) sejam poderosas, compiladores modernos de produção frequentemente optam por scanners manuais. Cite duas vantagens de se implementar um scanner manualmente em vez de utilizar geradores automáticos.
Escreva as expressões regulares que representam os seguintes padrões léxicos:
- (a) Regex para reconhecer números binários. Sequências de um ou mais dígitos
0ou1. - (b) Regex para nomes de arquivos de cabeçalho/fonte em C. Os nomes de arquivos que consistem em uma ou mais letras e terminam obrigatoriamente com a extensão
.cou.h(ex:main.c,lib.h). - (c) Expressão que comece com a letra
T, seguida de qualquer quantidade de letras ou dígitos, mas não pode terminar com um dígito (ex:Tvar,T10x, mas nãoT10). - (d) Expressão para comentários em linha que começam com
//e são seguidos por qualquer sequência de caracteres (assuma que o caractere de nova linha encerra o padrão). - (e) Uma expressão única que reconheça apenas as strings
&&(AND),||(OR) ou!(NOT). Note que precisará escapar o ou | do OR e o do regex.
- (a) Regex para reconhecer números binários. Sequências de um ou mais dígitos
Próximos passos5.9
No próximo capítulo, Lab - Configurando o Setup, sairemos da teoria para a prática. Daremos início à construção da base do código do nosso compilador utilizando a linguagem C. Definiremos a estrutura do projeto e organizaremos os arquivos de cabeçalho do nosso código.